1. HDFS對底層的磁盤存儲如何選擇的?
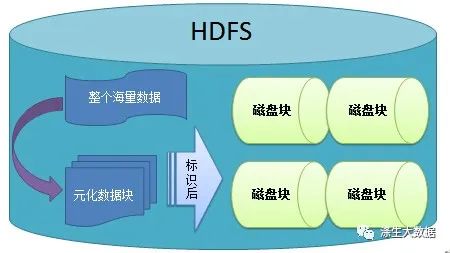
一個HDFS集群,會有很多個datanode節點,每個datanode節點會掛載很多塊磁盤。HDFS在存儲數據時如何動態負載均衡最優化地往每個datanode,每個磁盤上存儲數據呢?
其實沒啥,DataNode在運行過程中,為了計算DN的capacity使用量,實現數據存儲的動態均衡,DN會對已配置的數據存儲路徑(dfs.datanode.data.dir)進行du -sk操作,以此獲得capacity使用量匯報給NN中,然后NN就知道哪些DN有空間能被寫數據進去,哪些是空間不足的。
為了保證數據使用量的近實時性,目前DN是以默認10分鐘的間隔時間執行一次。假設按照一個DN節點12個數據目錄對應12塊盤的情況,就會有12個du操作在每個10分鐘內都會執行一次。在datanode存儲的數據使用率比較高的時候,會十分消耗性能。直接引發阻塞io,系統load直線增高。
這種問題在大規模的集群中是很常見的,下面是針對線上(hadoop2.6版本的)簡易零時的優化手段。說明:此問題僅存在于低于hadoop2.8版本,高于此版本已經修復。
https://issues.apache.org/jira/browse/HADOOP-9884
如果碰到這種情況,升級不了集群版本,那么我們還有其他奇技淫巧嗎?
2.通過修改HDFS代碼實現優化
先回顧一下du,df的使用
du原理簡述:
du命令全程disk usage,它的統計原理在于將目標路徑下的當前沒有被刪除的文件進行大小累加,然后得出總使用量。這種計算方式在文件數量少時往往不會表現出什么問題。但是當目標路徑目錄多,文件多的時候,du會表現出明顯的時間執行耗時。
df 原理簡述:
df命令統計值通過文件系統獲取的。df命令的弊端是它不能按照具體目錄進行使用量的統計。df是按照所在磁盤級別進行統計的。換句話說,用df命令在屬于同一塊物理盤的子路徑下執行df命令,獲取的值會是完全一致的。比較遺憾,這種情況將無法支持DataNode多block pool共用一塊盤的情況。
處理方式:使用 df 命令替換 du
捕獲到datanode執行過程中調用的 du -sk 命令,替換為df -k 。
實現腳本如下:
##將原始的 du指令更換名稱