日前,在AICC2018人工智能計(jì)算大會(huì)上,美國(guó)杜克大學(xué)終身副教授、美國(guó)自然科學(xué)基金委智能與可持續(xù)計(jì)算產(chǎn)學(xué)合作中心主任陳怡然先生做了關(guān)于《人工智能芯片設(shè)計(jì)中的挑戰(zhàn)》主題演講,引發(fā)廣泛討論。
以下為陳怡然教授演講摘錄:
剛才會(huì)議開始的時(shí)候王恩東院士講我們有三次浪潮,這三次浪潮分別代表了不同算法的突破,我只經(jīng)歷了一次浪潮。這三次浪潮延續(xù)了70年的時(shí)間,從1940年到現(xiàn)在每次浪潮都伴隨著新的算法模型的興起,但是它不是孤立存在的,伴隨著計(jì)算能力的不斷提高。如果大家把眼光放到技術(shù)計(jì)算來看,計(jì)算技術(shù)的發(fā)展其實(shí)是一個(gè)持續(xù)發(fā)展的現(xiàn)象,過去五年如果看到GPU單板計(jì)算能力的提高,大概只提高了3-4倍,但模型參數(shù)總數(shù)目提高了幾百上千倍。所以我們面臨的調(diào)整你是要了解人工智能應(yīng)用的硬件要求是什么,芯片要怎么去設(shè)計(jì)才能變得更有效,從而彌補(bǔ)摩爾定律本身的發(fā)展和參數(shù)上的增加所帶來的差別。

馮諾伊曼體系有以下幾個(gè)特點(diǎn):存儲(chǔ)和計(jì)算是分離的,控制單元可以把數(shù)據(jù)從內(nèi)存調(diào)到計(jì)算單元,計(jì)算單元經(jīng)過處理以后再傳回到內(nèi)存。過去有大量的科學(xué)計(jì)算的應(yīng)用,非常成功。但是這種單線程在馮諾伊曼體系里受制于運(yùn)行指令之間的數(shù)據(jù)依賴的影響,當(dāng)你大規(guī)模運(yùn)行的時(shí)候會(huì)發(fā)現(xiàn)性能會(huì)掉得非常厲害。從此我們就做到多核,多核又帶來了一些新的問題,比如帶寬或瓶頸的問題,片上計(jì)算能力不斷提高,但是內(nèi)存帶寬又不斷受限,往往不能達(dá)到最高的有效的計(jì)算。當(dāng)然還有另外一個(gè)問題是功率密度的問題,我最近跟學(xué)生開了一個(gè)笑話,我上大學(xué)的時(shí)候攢機(jī)器,一個(gè)CPU100美元-200美元,現(xiàn)在還是這個(gè)價(jià)格甚至更便宜了,我當(dāng)時(shí)在中關(guān)村買一個(gè)風(fēng)扇只要幾毛錢,現(xiàn)在好的要幾十美元,很貴了,做CPU真的比做風(fēng)扇賺得多。

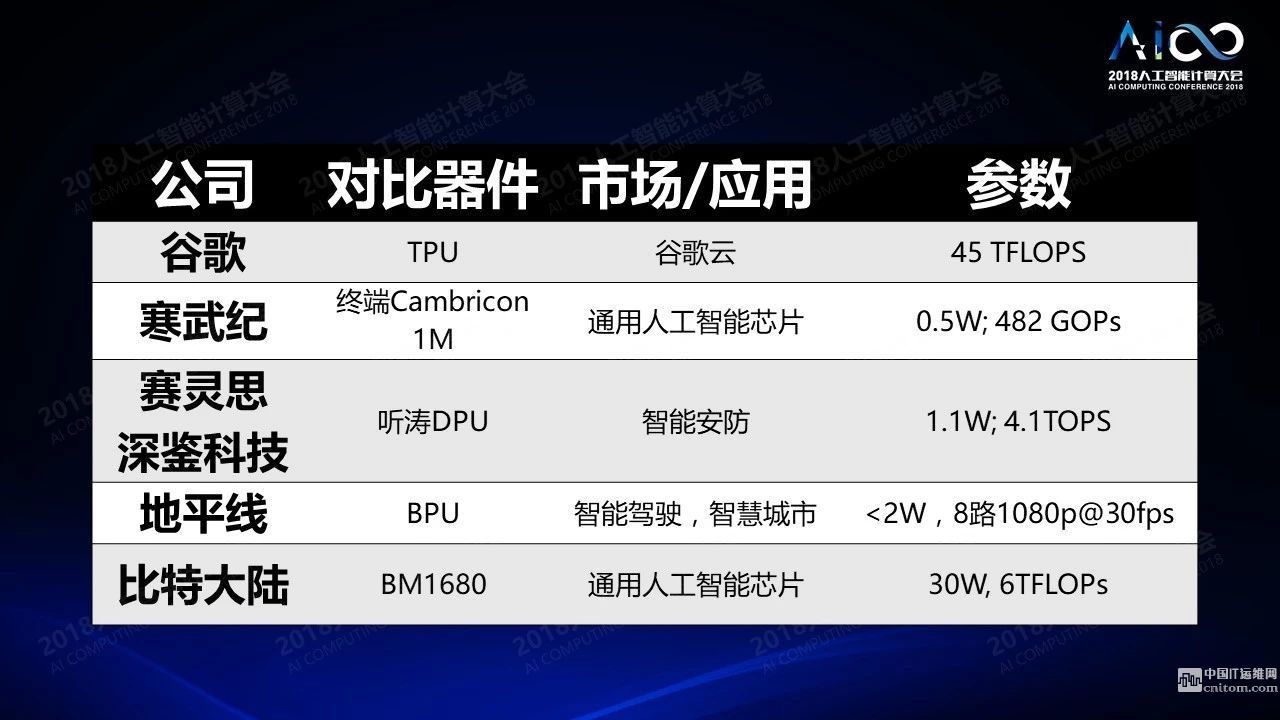
我們發(fā)現(xiàn)越來越多的應(yīng)用需要更多新式的芯片進(jìn)行處理,這種處理的要求是跟傳統(tǒng)的CPU和GPU不太一樣,雖然這些運(yùn)算也可以用GPU來做加速。GPU本身是一個(gè)流式的處理器,它可以有效進(jìn)行向量之間的運(yùn)算,如果我們用n表示計(jì)算的能力,它把每個(gè)規(guī)模為n計(jì)算變?yōu)榱?。從這個(gè)角度出發(fā)大家用FPGA進(jìn)一步加速計(jì)算的過程,比如國(guó)內(nèi)比較有名的深鑒科技用FPGA進(jìn)行網(wǎng)絡(luò)神經(jīng)的加速設(shè)計(jì),谷歌TPU通過脈沖陣列的形式加速神經(jīng)網(wǎng)絡(luò)的計(jì)算,國(guó)內(nèi)另外一家公司寒武紀(jì)設(shè)置了專門的指令集,對(duì)于不同的向量與向量之間,向量與矩陣之間進(jìn)行加速。要說明大家對(duì)于不同的架構(gòu)的應(yīng)用場(chǎng)景也基本是不一樣的,這只是列了其中一些比較有代表性的例子,此外還有非常多。芯片設(shè)計(jì)的參數(shù)集中在計(jì)算性能,還有功耗,最終數(shù)據(jù)的吞吐量等等。所有這些參數(shù)都是我們關(guān)心的問題。

挑戰(zhàn)1:大容量存儲(chǔ)和高密度計(jì)算
我們的第一個(gè)挑戰(zhàn),大容量存儲(chǔ)和高密度計(jì)算,當(dāng)神經(jīng)深度學(xué)習(xí)網(wǎng)絡(luò)的復(fù)雜度越來越高的時(shí)候,我們會(huì)面臨一個(gè)問題:你的參數(shù)越來越多,你該怎么辦?大家常見的一個(gè)技術(shù)是做剪枝:神經(jīng)網(wǎng)絡(luò)里面有大量的冗余,這種冗余是可以被去除的,去除以后基本不會(huì)影響計(jì)算精度。比如簡(jiǎn)單的想法就是如果我知道有一個(gè)權(quán)重很小,對(duì)于輸出結(jié)果沒有太大影響,那就可以去掉。你在去除的過程中遇到這樣一個(gè)問題:這樣的權(quán)重在訓(xùn)練之后是隨機(jī)的分布在整個(gè)向量空間里。當(dāng)你把這個(gè)稀疏網(wǎng)絡(luò)存在一個(gè)計(jì)算機(jī)存儲(chǔ)系統(tǒng)的時(shí)候讀取這個(gè)網(wǎng)絡(luò)會(huì)帶來大量的訪問缺失。比如當(dāng)你讀取一個(gè)數(shù)據(jù)之后,下一個(gè)數(shù)據(jù)往往并不是計(jì)算所需要的,這就帶來了存儲(chǔ)器訪存的缺失。

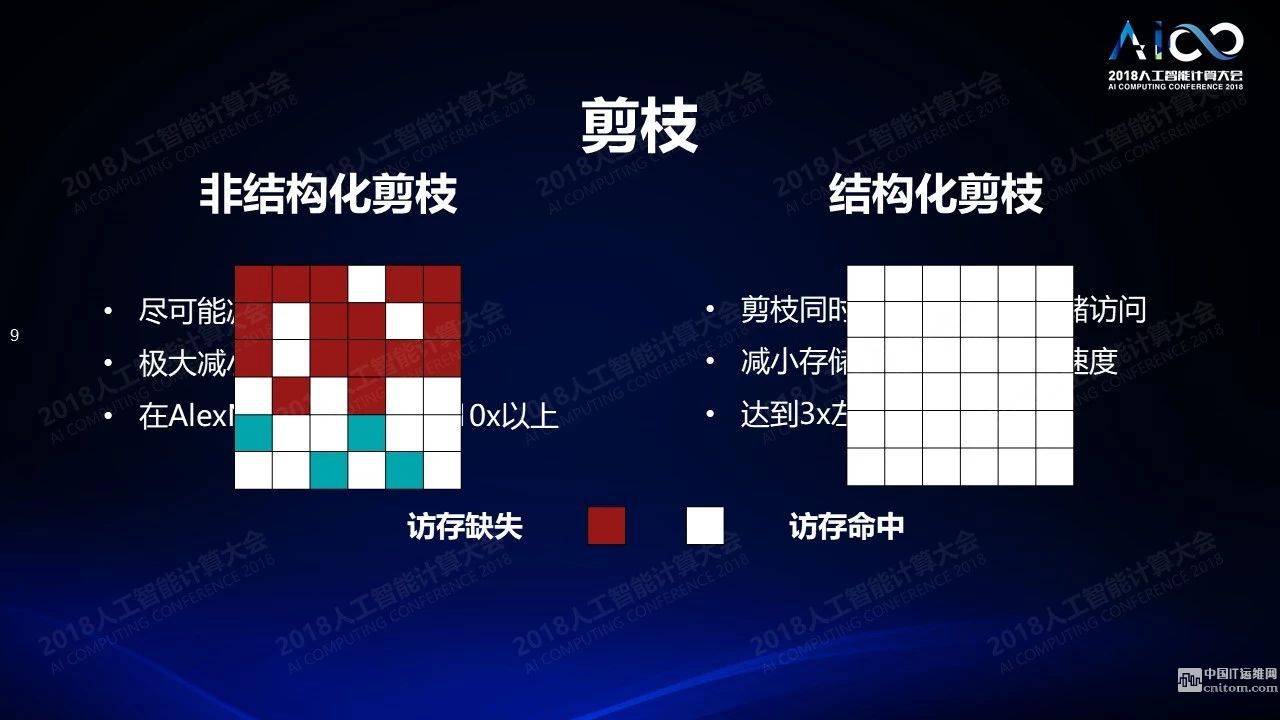
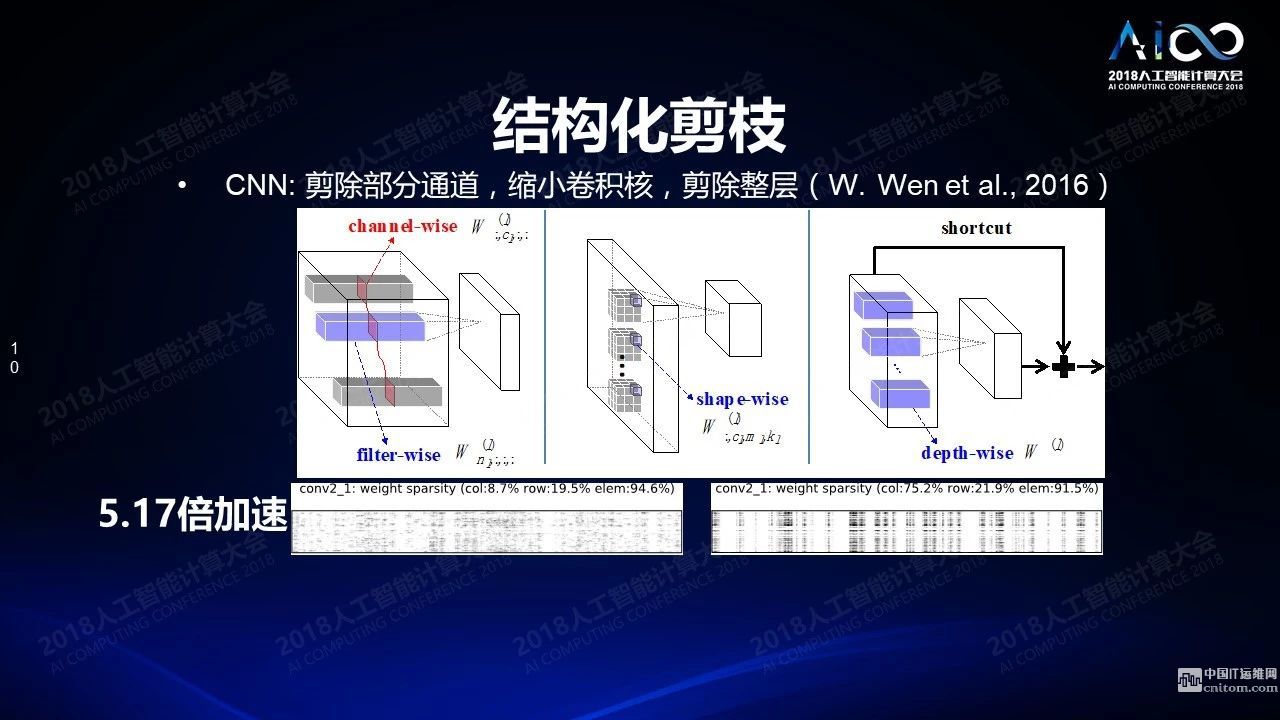
我們可以通過軟件的方式解決這個(gè)問題,比如在數(shù)據(jù)結(jié)構(gòu)上打補(bǔ)丁。這些在我看來并不是很聰明的辦法,沒有解決根本性的問題。根本性的解決方案是結(jié)構(gòu)化的剪枝:當(dāng)你在去掉這些權(quán)重的時(shí)候如果不是一個(gè)一個(gè)單獨(dú)的隨機(jī)的去掉而是一塊一塊的去掉,盡量介紹對(duì)它存儲(chǔ)方式的影響。這個(gè)工作是我們2016年NIPS的一篇文章《結(jié)構(gòu)稀疏化》,今年年初已經(jīng)被英特爾的芯片系統(tǒng)支持了。結(jié)構(gòu)稀疏化另外一個(gè)問題是什么樣的層次下做到稀疏化,可以把通道所對(duì)應(yīng)的權(quán)重整個(gè)去除掉,把卷積核對(duì)應(yīng)的權(quán)重整個(gè)去除掉,甚至整層去除掉,最后都會(huì)帶來結(jié)構(gòu)稀疏化的結(jié)果。下面兩張圖左邊是隨機(jī)去除的結(jié)果,右邊是結(jié)構(gòu)去除的結(jié)果,左邊和右邊相比可以帶來10倍的性能提升,這個(gè)工作是我們跟英特爾一塊做的,他們后來把這個(gè)技術(shù)在產(chǎn)品里給支持了。
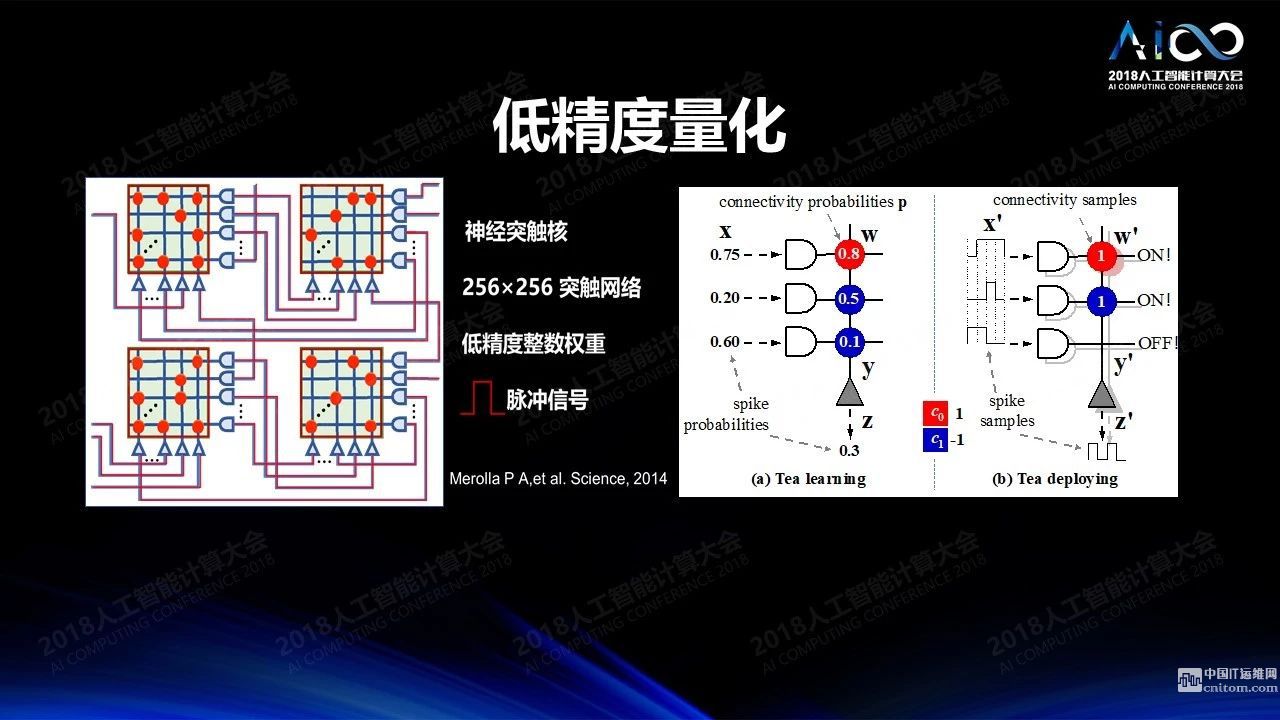
低精度:我們?cè)谟?xùn)練的時(shí)候需要高精度,但做推理的時(shí)候不一定需要高精度,低精度的運(yùn)算可以極大降低運(yùn)算的開銷,提升運(yùn)算的效率,又不怎么降低計(jì)算的準(zhǔn)確度。一個(gè)極端的例子是IBM的真北芯片,所有數(shù)據(jù)和權(quán)重都是通過三值來實(shí)現(xiàn)的,+1、-1和0,怎么仍然能達(dá)到比較高的精度呢?傳統(tǒng)意義上采用了冗余的設(shè)計(jì),比如輸入為0.75,如果有四個(gè)脈沖的位置,有3個(gè)脈沖出現(xiàn)就表達(dá)0.75。如果權(quán)重是0.8,那么我們就保留5個(gè)神經(jīng)網(wǎng)絡(luò)的拷貝,其中相應(yīng)的權(quán)重四個(gè)為1一個(gè)為0。這樣的結(jié)果是非常浪費(fèi)的,根本的解決方法不應(yīng)該是通過冗余的方式來設(shè)計(jì),應(yīng)該通過訓(xùn)練得到一個(gè)簡(jiǎn)單的三值網(wǎng)絡(luò)。我們來做一個(gè)小小的腦力體操,我們訓(xùn)練一個(gè)網(wǎng)絡(luò)的時(shí)候究竟是把它按照一個(gè)高精度的網(wǎng)絡(luò)來訓(xùn)練還是把它訓(xùn)練成所有的精度都盡可能靠近0和1,從而能夠理想的寫入只可以存三值的存儲(chǔ)空間。答案當(dāng)然是后者。如果我們能夠把訓(xùn)練網(wǎng)絡(luò)的時(shí)候就訓(xùn)練成一個(gè)三值網(wǎng)絡(luò),我們訓(xùn)練所得一定是把它寫入到硬件系統(tǒng)之后的所得。所以我們?cè)谟?xùn)練的時(shí)候?qū)γ總€(gè)權(quán)重做處理,使得所有訓(xùn)練后的權(quán)重都向0和1靠攏,結(jié)果就會(huì)變得比較好。我們通過這種方式在IBM達(dá)到性能6-7倍的提升,我們所做的其實(shí)就是改掉一行程序。
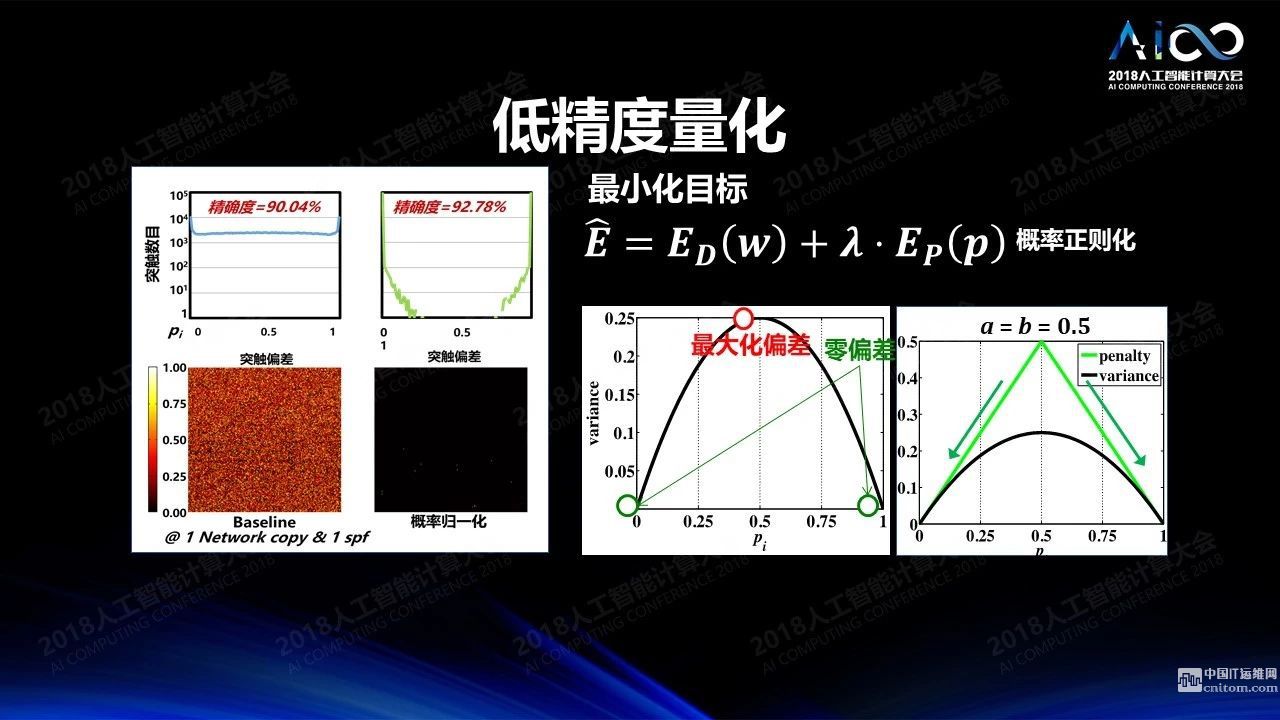
低精度神經(jīng)網(wǎng)絡(luò)訓(xùn)練在分布式系統(tǒng)上的應(yīng)用通常使用參數(shù)服務(wù)器。我們有很多神經(jīng)網(wǎng)絡(luò)的拷貝,這些拷貝在每個(gè)節(jié)點(diǎn)上都會(huì)用不同的數(shù)據(jù)來訓(xùn)練,一段時(shí)間之后我們把訓(xùn)練的結(jié)果發(fā)送到參數(shù)服務(wù)器來同步,再把同步后的結(jié)果分發(fā)下去。但當(dāng)系統(tǒng)特別大的時(shí)候就會(huì)遇到一個(gè)問題:它的規(guī)模不能持續(xù)擴(kuò)大,因?yàn)榇罅康耐ㄐ艓挾枷脑诠?jié)點(diǎn)和參數(shù)服務(wù)器互之間的數(shù)據(jù)傳輸,我們?cè)趺唇档烷_銷?當(dāng)然如果用0、+1、-1來表示數(shù)據(jù)的話數(shù)據(jù)量就會(huì)變得非常少。但是這樣的三值只能表示方向不表示數(shù)據(jù)大小。我們實(shí)際測(cè)試中發(fā)現(xiàn)其實(shí)所有數(shù)據(jù)傳輸,當(dāng)數(shù)據(jù)足夠大的情況下其實(shí)都滿足于某一種分布。因此數(shù)據(jù)比較大的情況下只需要傳大概2到3個(gè)值,剩下的只要傳方向,就可以在另外一端把數(shù)據(jù)整個(gè)恢復(fù)出來,這樣就完全不必要傳我們的數(shù)據(jù)采樣而只需要傳分布就可以了,這樣的結(jié)果是我們?cè)?28個(gè)節(jié)點(diǎn)的GPU集群上可以達(dá)到3倍左右的訓(xùn)練加速,性能精確度大概降低了不到2%。
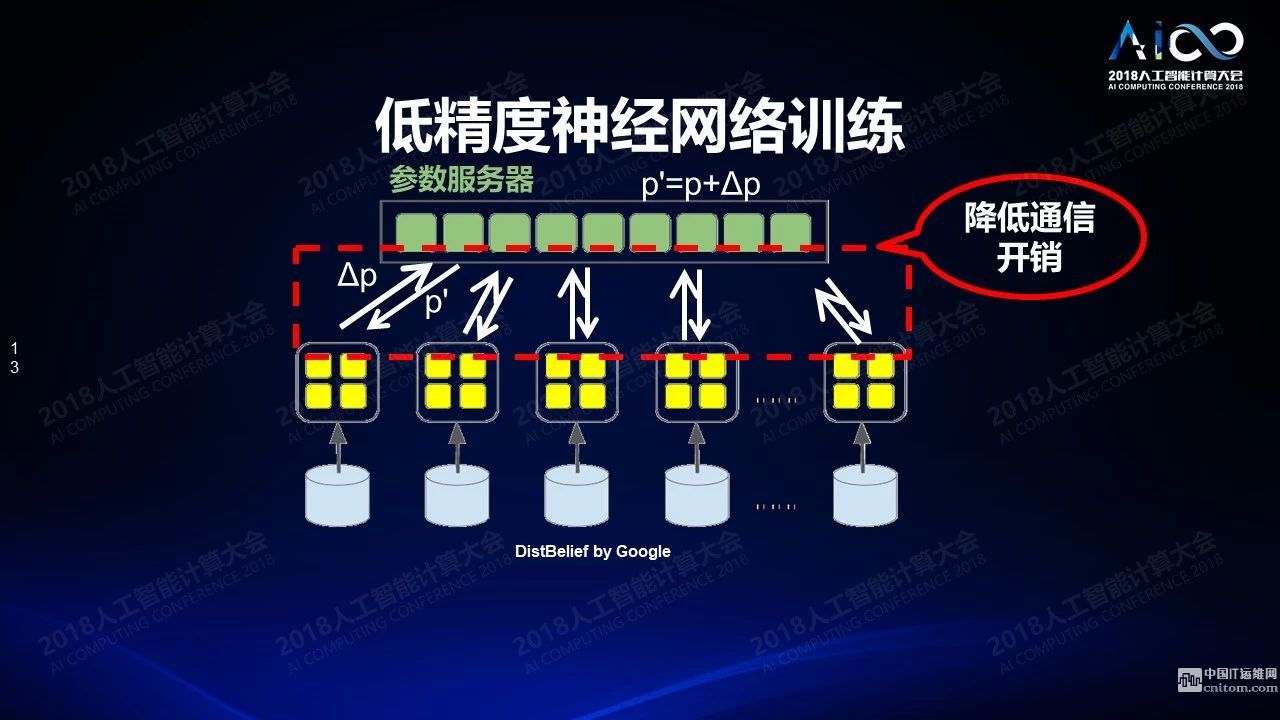


挑戰(zhàn)2:面臨特定領(lǐng)域的架構(gòu)設(shè)計(jì)
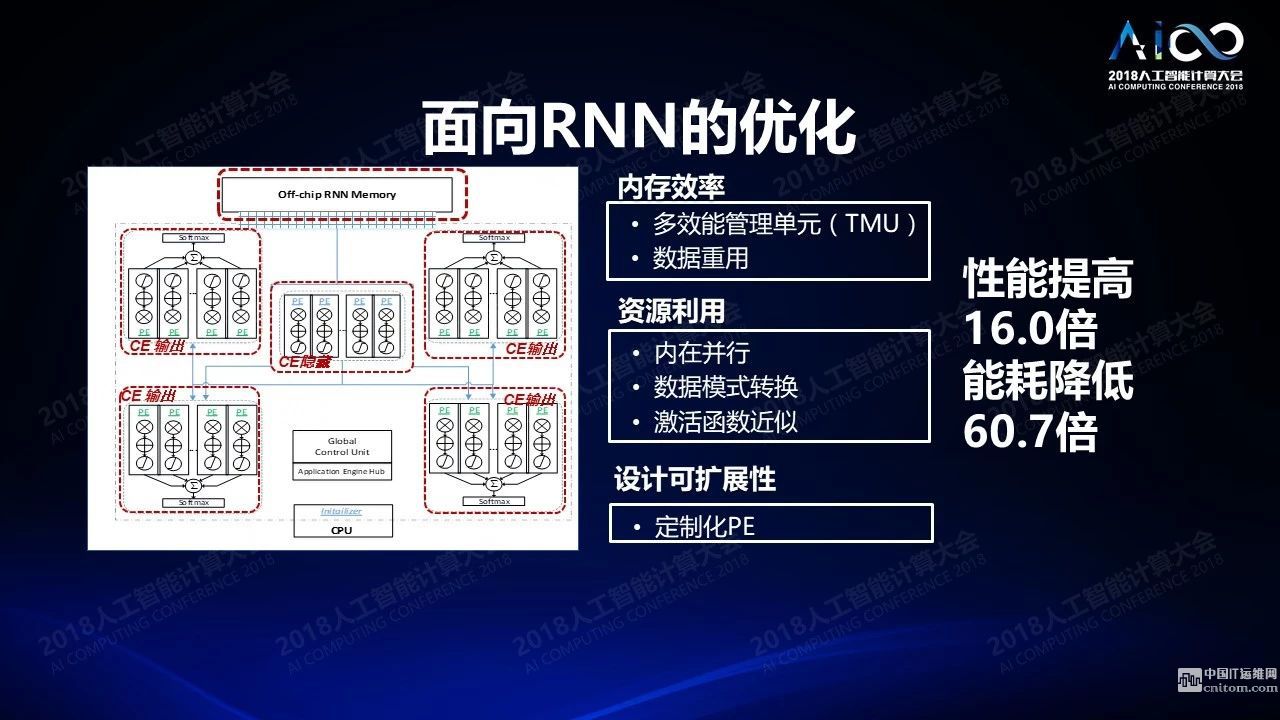
我們第二個(gè)挑戰(zhàn)是面臨特定領(lǐng)域的架構(gòu)設(shè)計(jì),因?yàn)槲覀兊膱?chǎng)景越來越豐富,而這些場(chǎng)景的計(jì)算需求是完全不一樣的。比如我們從圖像處理場(chǎng)景得到的知識(shí),當(dāng)我們面臨語(yǔ)音應(yīng)用的時(shí)候它能夠重復(fù)使用的部分是非常有限的。所以我怎么樣通過對(duì)于不同的場(chǎng)景的理解設(shè)置不同的硬件架構(gòu)變得非常重要。舉一個(gè)簡(jiǎn)單的例子,很多人用FPGA做圖象處理,而圖像處理不需要考慮時(shí)域上的信號(hào)傳播。這在語(yǔ)音處理的時(shí)候是必不可少。所以在2015年的時(shí)候我們?cè)贔CCM,是FPGA領(lǐng)域的一個(gè)頂級(jí)會(huì)議上發(fā)布了關(guān)于RNN的優(yōu)化。我們通過內(nèi)存效率提升,激活函數(shù)的近似和提高基礎(chǔ)單元設(shè)計(jì)的可擴(kuò)展性,達(dá)到了相當(dāng)于CPU性能16倍的提高,而功耗降低了60倍,這是比較典型的例子。

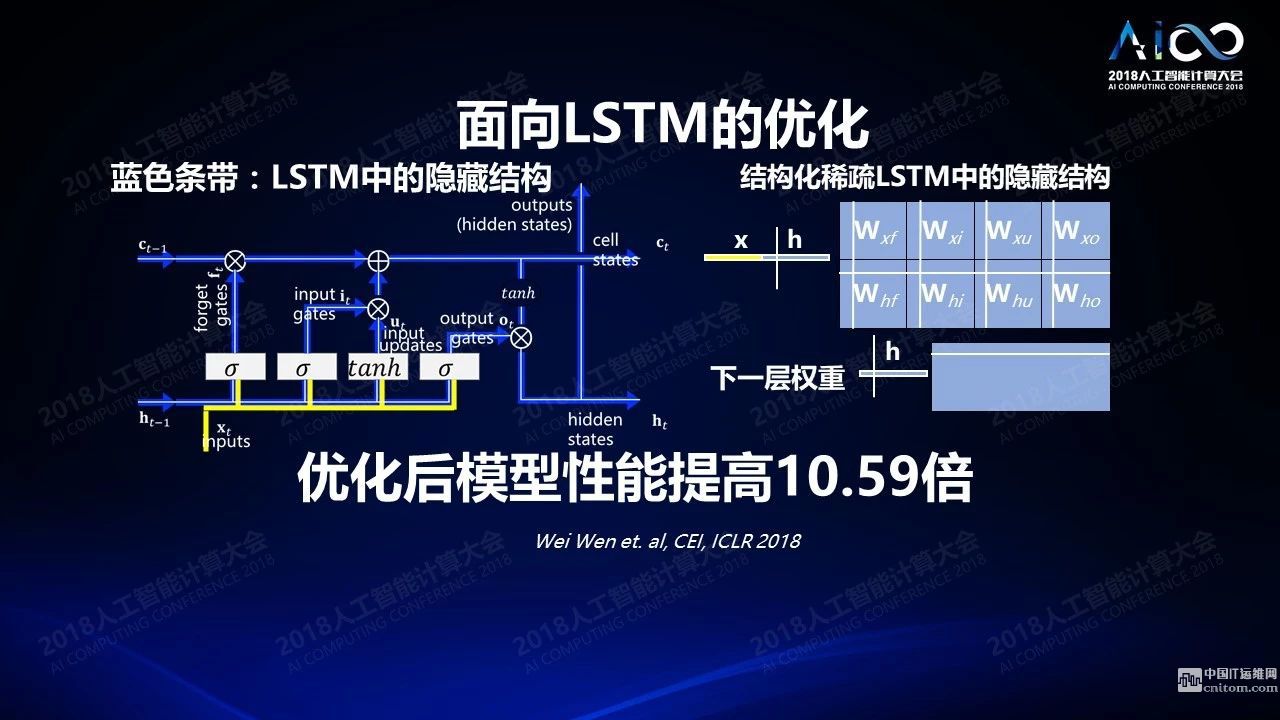
不僅如此,我們?cè)谒惴ㄉ弦部梢宰鱿鄳?yīng)的轉(zhuǎn)換,今年我們發(fā)布了一篇文章,在語(yǔ)音的LSTM的模型上我們直接結(jié)構(gòu)稀疏化它的隱藏結(jié)構(gòu),這種隱藏結(jié)構(gòu)的稀疏可以達(dá)到10倍性能的提升。即使在一些復(fù)雜的自然語(yǔ)言處理場(chǎng)景下我們也可以帶來20-40%左右的性能提升,精確度做到了大概只有1%的損失。現(xiàn)在這個(gè)技術(shù)已經(jīng)被某大公司直接用在了他們的硬件設(shè)計(jì)上。
最近GAN比較熱,它可以很有效的通過兩個(gè)網(wǎng)絡(luò)相互之間的學(xué)習(xí)來生成一些現(xiàn)實(shí)場(chǎng)景中不存在但是又真實(shí)可信的數(shù)據(jù),GAN的應(yīng)用在非監(jiān)督學(xué)習(xí)上會(huì)有大量的應(yīng)用和突破。我們最近有一篇文章在講我們體系結(jié)構(gòu)上也可以生成一種新的流水線,使得對(duì)于GAN的訓(xùn)練效率有很大的提高。
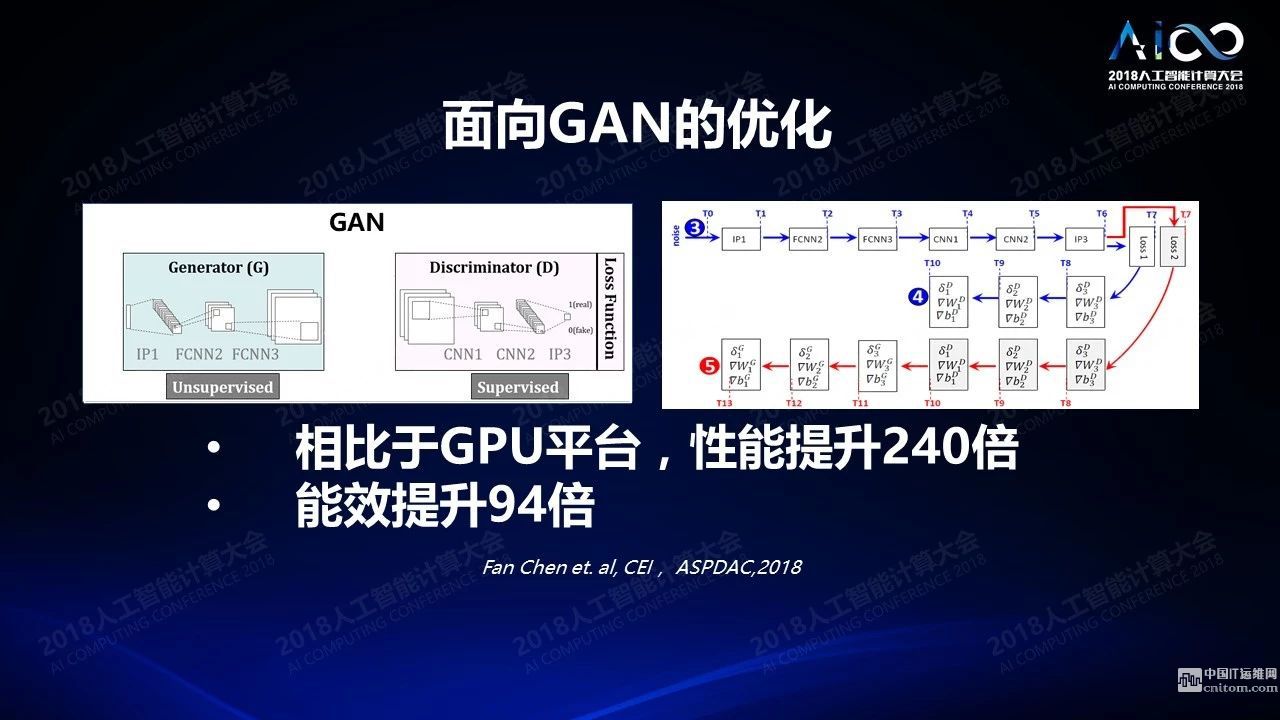
挑戰(zhàn)3:“云-終端”平臺(tái)特點(diǎn)不同
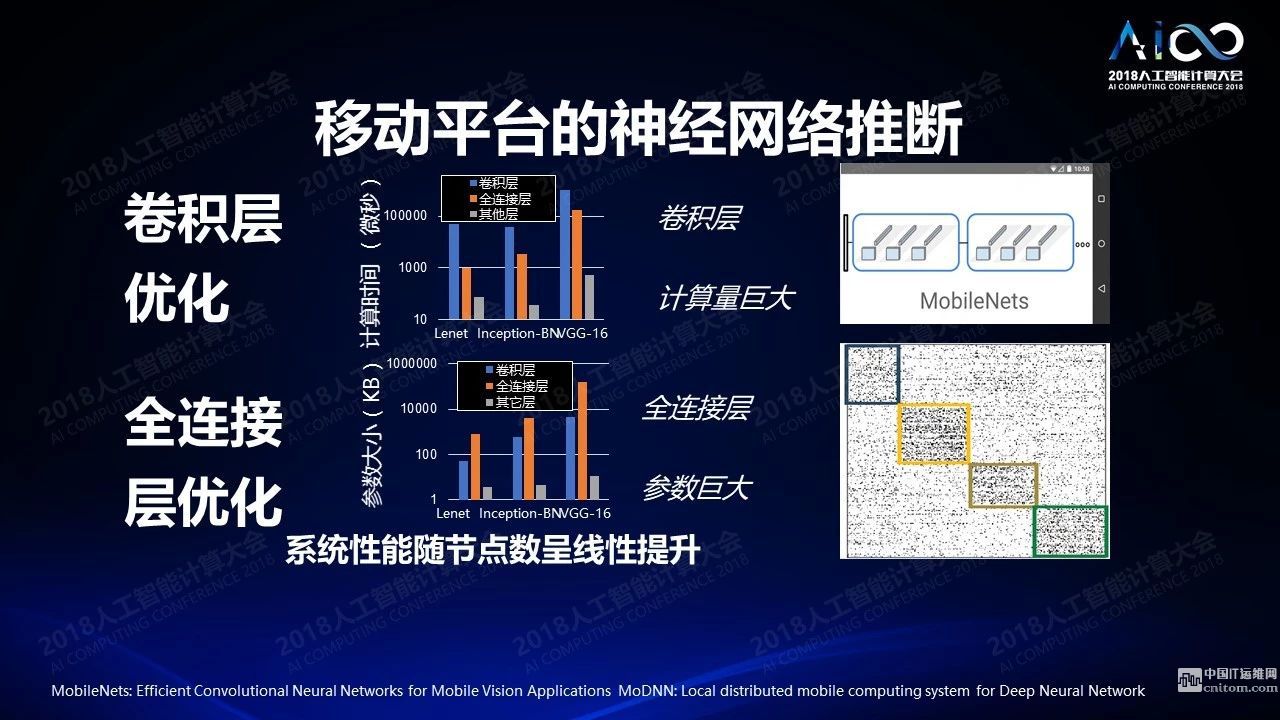
云和終端是不一樣的,云端和終端的設(shè)計(jì)完全不同,云端需要對(duì)海量數(shù)據(jù)進(jìn)行處理,要進(jìn)行存儲(chǔ),要進(jìn)行訓(xùn)練,要高并行高帶寬,終端上首先要采集,然后做終端的推理,還要做一些簡(jiǎn)單的訓(xùn)練,還關(guān)心安全性、低能耗、低延時(shí)等等的處理。我們?cè)诤芏嗄昵伴_始做移動(dòng)計(jì)算,我們最近開始轉(zhuǎn)移到移動(dòng)平臺(tái)的神經(jīng)網(wǎng)絡(luò)的訓(xùn)練以及推理上來,去年有一篇文章拿了最佳論文獎(jiǎng),題目是分布式移動(dòng)端的訓(xùn)練。它有點(diǎn)像移動(dòng)端的參數(shù)服務(wù)器:我有一個(gè)手機(jī)對(duì)其他所有手機(jī)進(jìn)行管理和同步,各個(gè)手機(jī)之間進(jìn)行并行的訓(xùn)練,然后把低精度計(jì)算運(yùn)用在上面。一些精確的分析會(huì)發(fā)現(xiàn)神經(jīng)網(wǎng)絡(luò)的各個(gè)層相對(duì)于資源的要求是完全不一樣的。比如卷積層貢獻(xiàn)了絕大多數(shù)的計(jì)算的開銷,而全連接層貢獻(xiàn)了絕大多數(shù)存儲(chǔ)的開銷。所以你在設(shè)計(jì)的過程中就需要考慮這樣的差別。如果你在做稀疏化的時(shí)候,稀疏化之后可以對(duì)計(jì)算本身做一個(gè)聚類,這樣聚類之后的比較復(fù)雜的比較密集的網(wǎng)絡(luò)可以部署到同一個(gè)節(jié)點(diǎn),減少節(jié)點(diǎn)之間相互傳輸?shù)拈_銷。

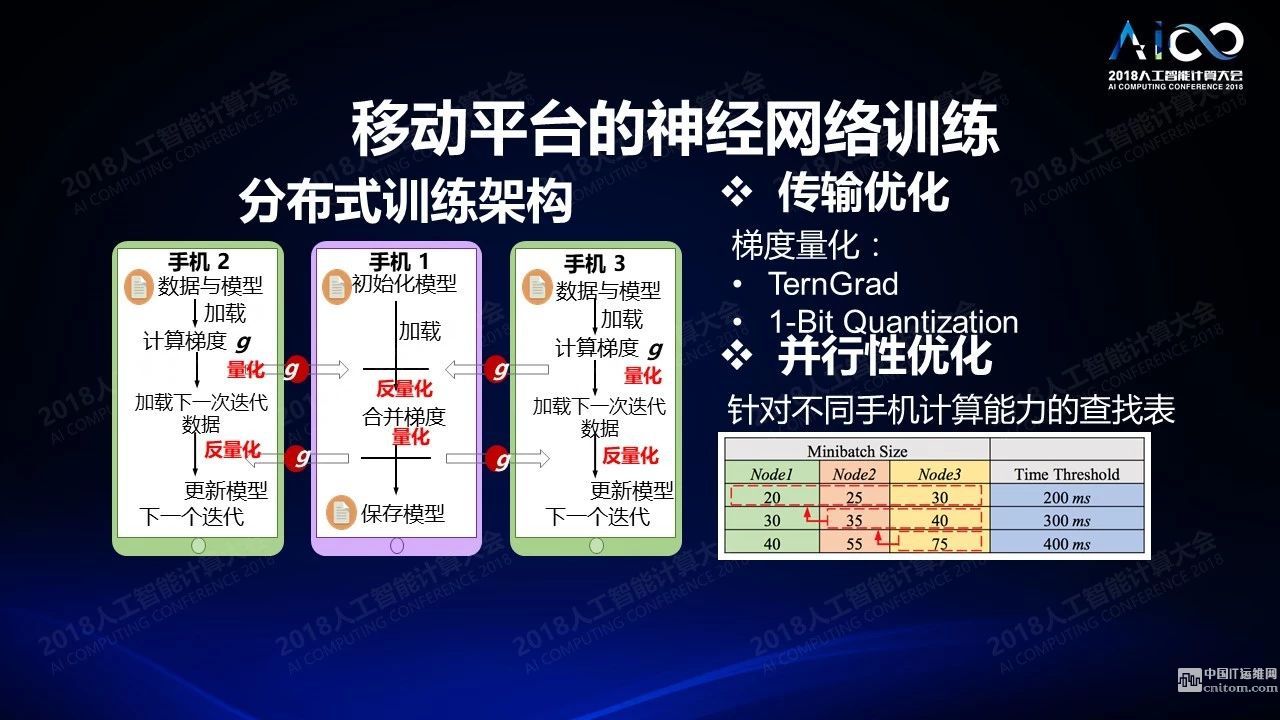
另外說盡管它是一個(gè)中心化的網(wǎng)絡(luò),我們也可以把它做成一個(gè)去中心化的網(wǎng)絡(luò)或半去中心化的網(wǎng)絡(luò),來提高它的安全性,降低對(duì)于中心節(jié)點(diǎn)的應(yīng)用。你還需要考慮在節(jié)點(diǎn)相互之間的傳輸?shù)拈_銷,因?yàn)槲覀冎缹?duì)于移動(dòng)網(wǎng)絡(luò)來講建立網(wǎng)絡(luò)之間相互的通道是非常昂貴的。我們可以隨著節(jié)點(diǎn)數(shù)目的增長(zhǎng)基本達(dá)到線性的提升,這是不太容易做到的事情。
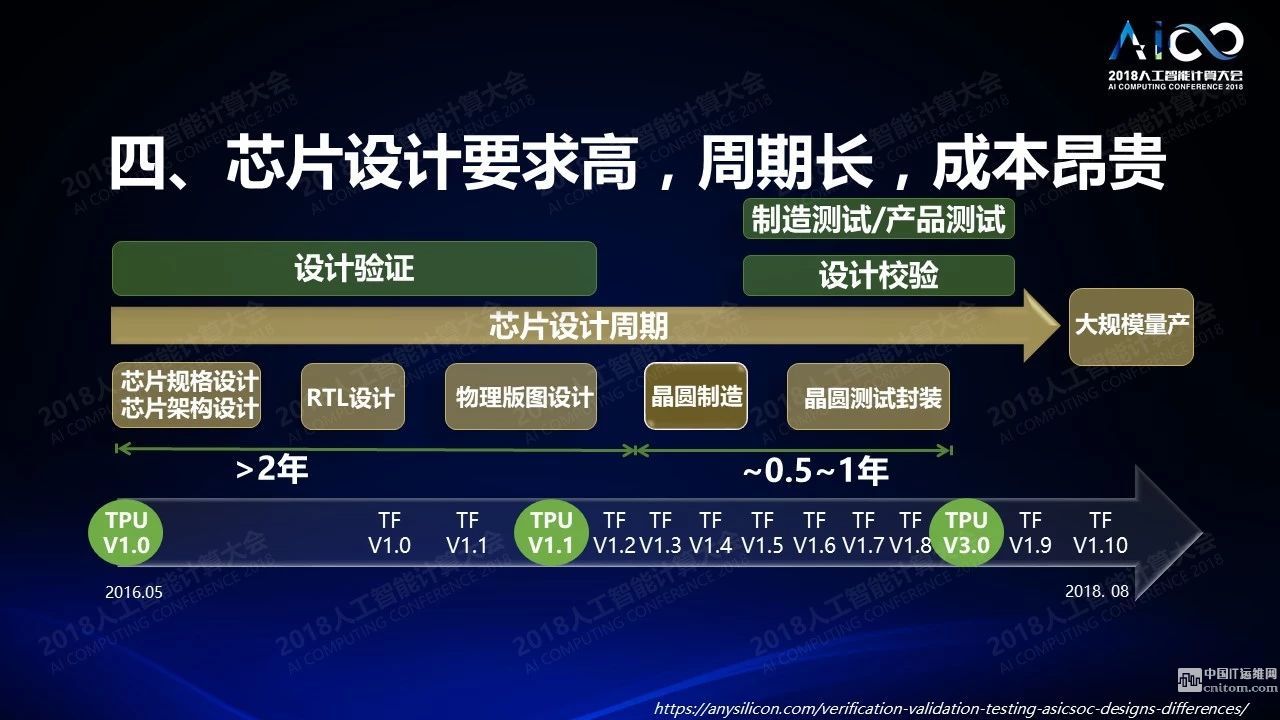
挑戰(zhàn)4:芯片設(shè)計(jì)要求高,周期長(zhǎng),成本昂貴
這是一個(gè)芯片周期的圖,從芯片規(guī)格設(shè)計(jì)芯片結(jié)構(gòu)設(shè)計(jì)、RTL設(shè)計(jì)、物理半途設(shè)計(jì)、晶圓制造、晶圓測(cè)試封裝,需要2到3年時(shí)間,正常情況下這段時(shí)間里軟件會(huì)有一個(gè)非常快速的發(fā)展。下面這張表是如果你看到TPU生產(chǎn)設(shè)計(jì)的周期和Tensorflow的周期,兩種不同的TPU版本之間Tensorflow已經(jīng)更新了7到8個(gè)版本,這么長(zhǎng)的周期能夠支持在這個(gè)周期里新的軟件版本的更新是非常具有挑戰(zhàn)性的問題。
其中一個(gè)解決方案是可以通過AI本身去加速芯片的設(shè)計(jì),最近我們?cè)诟ミ_(dá)做一個(gè)合作,通過AI的設(shè)計(jì)提高版圖的效率,我們把不同的AI的算法,像SVM和比較復(fù)雜的神經(jīng)網(wǎng)絡(luò)包括強(qiáng)化學(xué)習(xí),做了一個(gè)對(duì)比。這是一個(gè)最近非常熱門的話題,因?yàn)槊绹?guó)最近有一個(gè)項(xiàng)目,如果從最開始芯片定義到設(shè)計(jì)完成包括系統(tǒng)級(jí)封裝的設(shè)計(jì),希望是24小時(shí)無(wú)人值守,這是一件非常不容易的事情。對(duì)一個(gè)芯片,它的生命周期大概有三年時(shí)間,芯片從生產(chǎn)出來到產(chǎn)品消亡,三年里真正掙錢的時(shí)間是12-18個(gè)月,你怎么在12-18個(gè)月里降低成本提高利潤(rùn)率完成這個(gè)周期的迭代,AI技術(shù)可以做出大量的貢獻(xiàn)。
挑戰(zhàn)5:架構(gòu)及工藝面臨的挑戰(zhàn)
最后一個(gè)問題是架構(gòu)及工藝面臨的挑戰(zhàn)。這張圖是摩爾定律的另一個(gè)表達(dá)形式:隨著我們的工藝不斷的提升,從90納米到10納米,每代邏輯門生產(chǎn)的成本到最后變得飽和。我們也許在速度上、功耗上會(huì)有提升,但單個(gè)邏輯生產(chǎn)的成本不會(huì)再有新的下降。這種情況下如果仍然用幾千甚至上萬(wàn)個(gè)晶體管去做一個(gè)比較簡(jiǎn)單的深度學(xué)習(xí)的邏輯,那你會(huì)發(fā)現(xiàn)到最后在成本上是得不償失的。英特爾一直在說我計(jì)劃發(fā)布多少納米的生產(chǎn)技術(shù),實(shí)際上永遠(yuǎn)是在延后的,越往下做越貴越不容易。
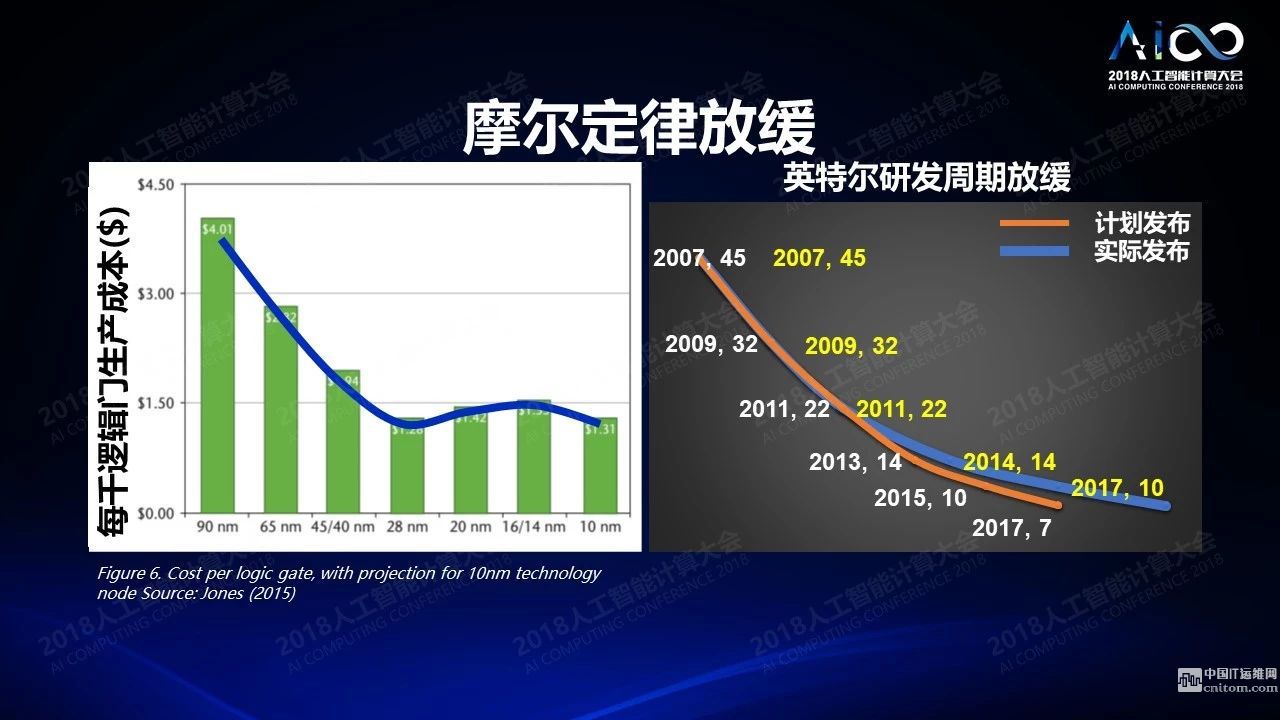
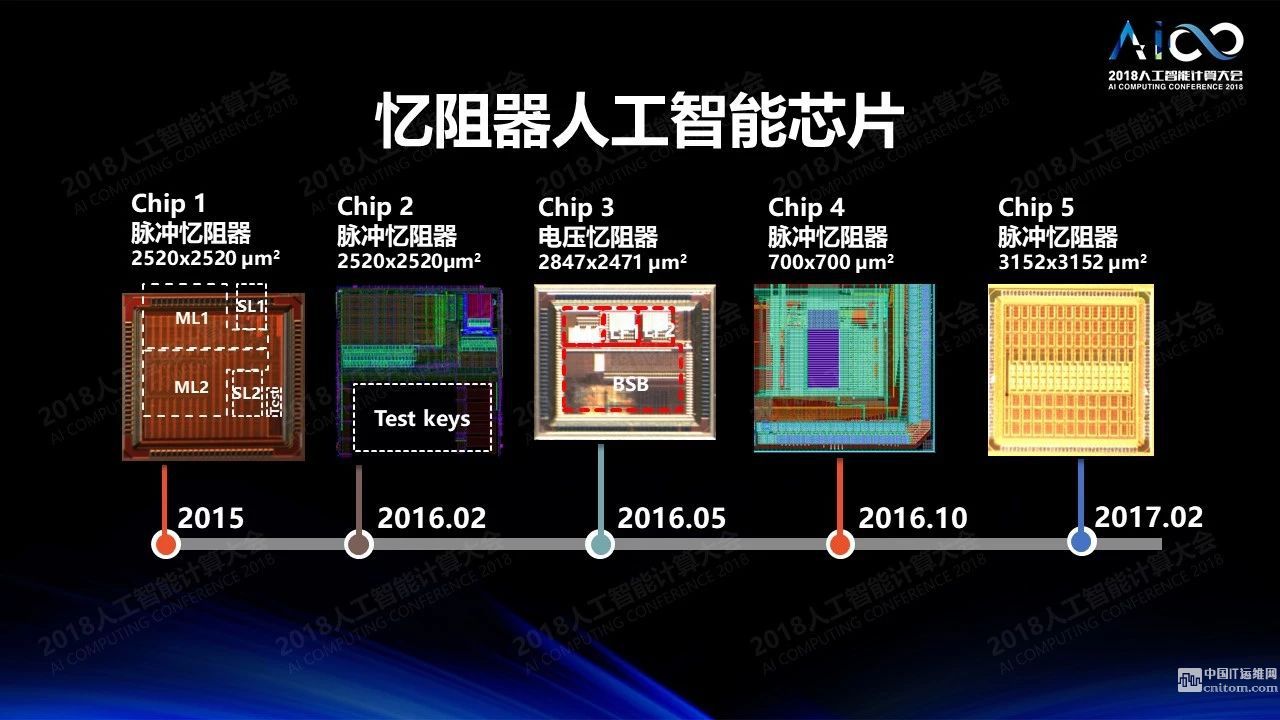
怎么解決這個(gè)問題?一個(gè)有趣的技術(shù)是憶阻器。這個(gè)北大的黃如老師、中科院的劉明老師他們也在做。這個(gè)器件有一些很有意思的特點(diǎn),它的特性非常像人的神經(jīng)網(wǎng)絡(luò)里面的神經(jīng)元,我們神經(jīng)突觸是連接兩個(gè)神經(jīng)元的。一個(gè)神經(jīng)元產(chǎn)生一個(gè)信號(hào)之后這個(gè)信號(hào)就會(huì)通經(jīng)神經(jīng)突觸到另一個(gè)神經(jīng)元上去,神經(jīng)突觸本身會(huì)把信號(hào)放大,倍數(shù)是可控的。憶阻器的特點(diǎn)是他的電阻值可以變化。當(dāng)你加了一個(gè)電壓之后產(chǎn)生的電流本身的幅度是可調(diào)的,有點(diǎn)像將兩個(gè)神經(jīng)元連在一起的神經(jīng)突觸,整個(gè)過程其實(shí)是在做乘法。這個(gè)器件只有幾個(gè)納米那么大。通過這個(gè)器件可以產(chǎn)生一個(gè)交叉互聯(lián)的結(jié)構(gòu),這種交叉互聯(lián)的結(jié)構(gòu)可以非常有效的把向量和矩陣相乘的形式加以變換,進(jìn)行有效的計(jì)算,可以一下子把n×n×n的計(jì)算一次性全部算出來,非常有效。過去很多年里我們一直在做這方面的研究,從單個(gè)器件一直做到模型、計(jì)算的原理,最近我們開始做芯片,這個(gè)圖上是其中的一些例子,用脈沖來表示數(shù)據(jù),到電壓憶阻器,一步步走過來。我去臺(tái)積電訪問,希望他們能支持我們這項(xiàng)研究。他們跟我講放心,他們也在做這個(gè)工作,如果摩爾定律放緩的話下面我們?cè)趺醋咧荒芸葱碌牟牧稀?br />
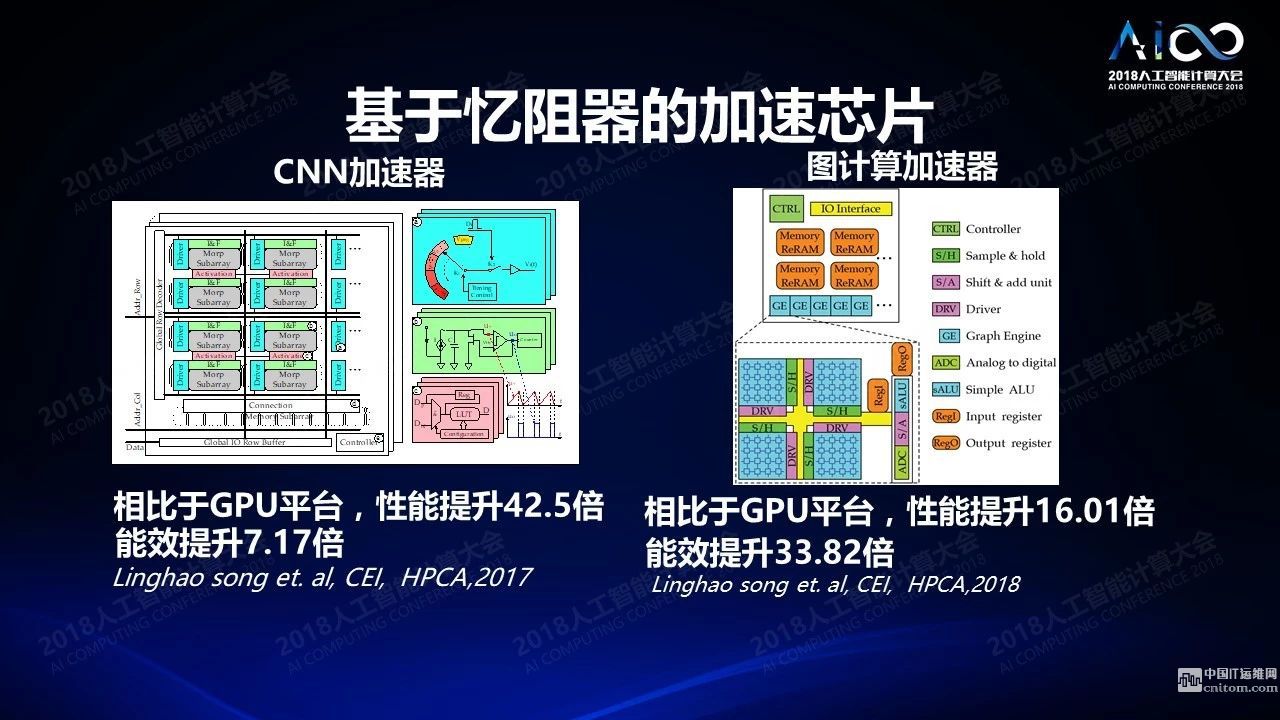
當(dāng)我們有了基于憶阻器的加速芯片之后做的另外一件事情是怎么把它真的用起來,把它做到新的計(jì)算架構(gòu)里面去。比如我可以把它以加速器的方式做到傳統(tǒng)的流水線里面去,相比GPU的平臺(tái)性能可以提高幾十倍,能效提高5到10倍。神經(jīng)網(wǎng)絡(luò)只是圖計(jì)算的一個(gè)特例,只是用某種圖的形式把這些計(jì)算連接起來,所以在圖計(jì)算上我們也可以做相應(yīng)的處理,不光是做深度優(yōu)先算法還可以做廣度優(yōu)先算法,我們都可以通過新型器件的方式加以計(jì)算,性能也有幾十倍左右的提升。這在現(xiàn)在這是非常熱門的領(lǐng)域,它的本質(zhì)是模擬計(jì)算,不是簡(jiǎn)單的通過傳統(tǒng)的科學(xué)計(jì)算的方式來完成計(jì)算,而是更有效的模擬神經(jīng)計(jì)算。
我們總結(jié)一下我們想做的事情,我經(jīng)常被問到一個(gè)問題,哪個(gè)平臺(tái)哪個(gè)技術(shù)在未來有可能贏得這場(chǎng)戰(zhàn)爭(zhēng),GPU公司還是基于新型器件的初創(chuàng)公司都希望知道答案,這意味著幾百億或幾千億的市場(chǎng)。為了回答這個(gè)問題我們總結(jié)了5個(gè)我們覺得比較重要的維度:AI硬件的特性、適應(yīng)性,性能功效、可編程性和可擴(kuò)展性。我們做了一個(gè)雷達(dá)圖進(jìn)行比較。無(wú)論是對(duì)于通用硬件平臺(tái)還是對(duì)于可編程器件沒有任何一個(gè)會(huì)在這五種特性里達(dá)到最優(yōu)的結(jié)果,都是有一兩個(gè)比較好或兩三個(gè)比較好,但另外一個(gè)比較差。回答這個(gè)問題,如果你問我哪個(gè)能贏,我首先要問你你要告訴我你的業(yè)務(wù)場(chǎng)景、你的數(shù)據(jù)類型、你愿意花的成本和你需要的計(jì)算開銷等等參數(shù)甚至技術(shù)本身的成熟度,然后我告訴你哪一種是最適合你的結(jié)果,這是我們覺得比較重要的一件事情,當(dāng)然也包括類腦架構(gòu)等比較新型的計(jì)算架構(gòu)。

AI芯片變得如此重要,最近我們?cè)诿绹?guó)自然科學(xué)資金委的思路下成立了一個(gè)新型可持續(xù)發(fā)展智能計(jì)算中心。我們覺得應(yīng)用來源于具體的場(chǎng)景,幫助我們理解需要什么樣的新的計(jì)算平臺(tái),需要什么樣的技術(shù),我們才能設(shè)計(jì)更多更好更有效的硬件來為這個(gè)目的服務(wù)。


