
一、數據分類分級管理概述
大數據時代,數據呈現多源異構的特點,價值各不相同,企業應根據數據的重要性、價值指數等方面予以區分,便于采取不同的數據保護措施,防止數據泄露。因此,數據分類分級管理是數據安全保護中的重要環節之一。
1.數據分類
數據分類是指根據組織數據的屬性或特征,將其按照一定的原則和方法進行區分和歸類,并建立起一定的分類體系和排列順序,以便更好地管理和使用組織數據的過程。
數據分類是數據保護工作中的關鍵部分之一,是建立統一、準確、完善的數據架構的基礎,是實現集中化、專業化、標準化數據管理的基礎。
2.數據分級
數據分級是指按照公共數據遭到破壞(包括攻擊、泄露、篡改、非法使用等)后對受侵害各體合法權益(國家安全、社會秩序、公共利益以及公民、法人和其他組織)的危害程度,對公共數據進行定級,為數據全生命周期管理進行的安全策略制定。
二、數據分類分級方法及細則
數據分類的常用方法:按關系分類,基于業務(來源)、基于內容、基于監管等。
數據分級的常用方法:按特性分級,基于價值(公開、內部、重要核心等)、基于敏感程度(公開、秘密、機密、絕密等)、基于司法影響范圍(大陸境內、跨區、跨境等)。
公用數據分類的常用方法:重要數據、個人及企業信息、業務數據。下面就來具體說明這三類公用數據。
重要數據:指一旦泄露則可導致危害國家安全,或危害公共利益、生命、財產安全,或危害國家關鍵基礎設施,或擾亂市場秩序,或可推論出國家秘密等的數據。
個人及企業信息:包含直接個人信息,以電子或其他方式記錄的、能夠單獨或與其他信息結合識別的自然人個人身份或企業的各種信息。
業務數據:包含企業或公共組織從事經營活動或例行社會管理功能、事務處理等一系列活動所產生的可存儲的數據。
根據上述公用數據的分類,重要數據分級、個人及企業信息分級和業務數據分級的方法分別如圖1、圖2和圖3所示。

圖1 重要數據分級方法示意圖

圖2 個人及企業信息分級方法示意圖
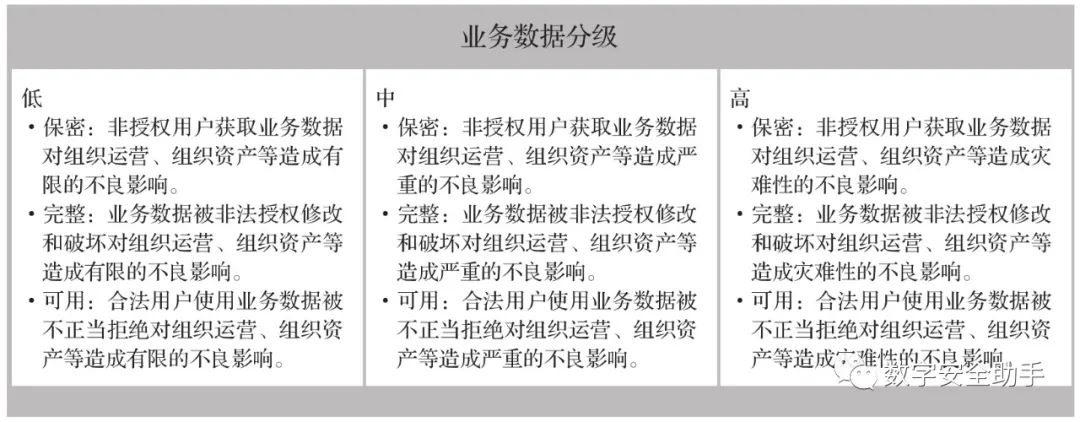
圖3 業務數據分級方法示意圖
企業可基于上述公用數據分類分級策略,結合自身業務和合規需求實際情況,規劃出適合企業自身的數據分類分級方法,建立適合組織自身的數據分類分級原則和方法,將數據按照重要程度進行分類。
然后在數據分類的基礎上,根據數據安全在受到破壞后對組織造成的影響和損失進行分級,如果組織層面已經具有相關的分類分級標準,則可酌情進行參考。在實際執行時,如果一次性做不到完全細粒度區分,則可以多步實現,循序漸進,不要設計過度復雜的方案。
企業自主分類分級可參考如圖4所示的思路,基于非敏感、敏感、涉密三個等級,對應上述重要數據的五個等級進行分級。

圖4 企業自主分類分級參考示意圖
三、常見數據分類分級標準
1.數據分類分級框架

來源:全國信息安全標準化技術委員會秘書處
2.分類標準
數據分類具有多種視角和維度,其主要目的是便于數據管理和使用。數據處理者進行數據分類時,應優先遵循國家、行業的數據分類要求,如果所在行業沒有行業數據分類規則,也可從組織經營維度進行數據分類。常見的數據分類維度,包括但不限于:
- 公民個人維度:將數據分為個人信息、非個人信息。
- 公共管理維度:將數據分為公共數據、社會數據。
- 信息傳播維度:將數據分為公共傳播信息、非公共傳播信息。
- 行業領域維度:將數據分為工業數據、電信數據、金融數據、交通數據、自然資源數據、衛生健康數據、教育數據、科技數據等。
- 組織經營維度:將數據分為用戶數據、業務數據、經營管理數據、系統運行和安全數據。
3.分級標準
從國家數據安全角度出發,數據分級基本框架分為一般數據、重要數據、核心數據三個級別。數據處理者可在基本框架定級的基礎上,結合行業數據分類分級規則或組織生產經營需求,考慮影響對象、影響程度兩個要素進行分級。各級別與影響對象、影響程度對應關系如下表所示:
|
基本級別 |
影響對象 |
|||
|
國家安全 |
公共利益 |
個人合法權益 |
組織合法權益 |
|
|
核心數據 |
一般危害、嚴重危害 |
嚴重危害 |
- |
- |
|
重要數據 |
輕微危害 |
一般危害、輕微危害 |
- |
- |
|
一般數據 |
無危害 |
無危害 |
無危害、輕微危害、一般危害、嚴重危害 |
無危害、輕微危害、一般危害、嚴重危害 |
來源:全國信息安全標準化技術委員會秘書處
下面列舉了幾種行業分級標準,影響程度從低到高:
- 政府數據:公開、內部、涉密。
- 金融數據:1級、2級、3級、4級、5級。
- 證券期貨數據:低、中、高、超高。
分類分級標準詳見:6000字,詳細解析數據的分類與分級
四、基于實際應用場景的分類技術
基于實際應用場景的數據分類主要包含以下幾種手段,其中,實際運用的技術手段可能涵蓋內容感知分類方法和情景感知分類方法中的多種方法。
標簽庫:根據分類分級規則建立標簽庫;既可以單獨成一個靜態庫,也可以直接在打標工具或系統后臺進行自定義配置。我們可以根據不同的文件格式類型建立標簽庫。比如,對于數據庫文件(.mdf),我們可以根據業務類型由大類到小類定義多個標簽。再比如,對于旅游業,我們可以建立(商業、旅游、用戶信息)的標簽庫。除了文件后綴名之外,我們還可以通過關鍵字、正則表達式等方式設定標簽規則。
結構化數據打標:用戶在建表時可以對字段標簽直接進行設置,基于數據庫的權限模型,對底層數據表的列權限進行控制。遍歷讀取數據庫的表名、列名,甚至是列的內容,結合標簽庫中設定的規則,或者自定義規則,對發現的表名、列名以更細的粒度對數據進行分類劃分。
非結構化數據打標:引入自然語言處理、數據挖掘和機器學習等技術,對內容進行識別,并與標簽庫相關的特征進行匹配,從而對非結構化的數據進行分類。
標注:首先,對一批文檔進行人工分類,以作為訓練集,然后利用機器學習算法,經過一段時間的學習之后,依據學習結果,對其他數據進行大批量打標。
訓練:計算機從這些文檔中挖掘出一些能夠有效分類的規則,生成分類器(即總結出來的規則集合)。
分類:將生成的分類器應用在有待分類的文檔集合中,獲取文檔的分類結果。由于機器學習方法在文本分類領域有著良好的實際表現,因此該方法已經成為該領域的主流。

 數據分類與訪問控制
數據分類與訪問控制
分級指的是在分類的基礎上,依據數據的敏感程度、影響范圍及自身的價值等對數據進行等級劃分,如上表所示,依據分類產生的標簽結果,可根據標簽定義數據的敏感程度,對數據進行進一步分級。
五、數據分類分級應用實踐舉例
數據平臺對數據分類分級的規劃實現架構:
平臺以“高密低訪”為基本原則,即高密的數據不能被低密的用戶訪問,高密的用戶可以訪問低密的數據。通過權限控制與數據脫敏相結合,可以完成更加精細化的數據安全管控場景。

類別管理:對于數據分類下的數據,可以針對不同的人設置不同的數據脫敏方式,達到相同數據展現給每個人不同的結果。在數據沒有設置級別時,也可以通過分類達到訪問控制的效果。
級別管理:通過對數據、用戶設置不同的級別,可以完成對用戶訪問權限的控制。當用戶級別大于等于數據級別時,用戶才可訪問。
展示層:用于驗證數據分類分級的安全管控效果。例如數據是否可訪問、是否脫敏。
應用舉例:
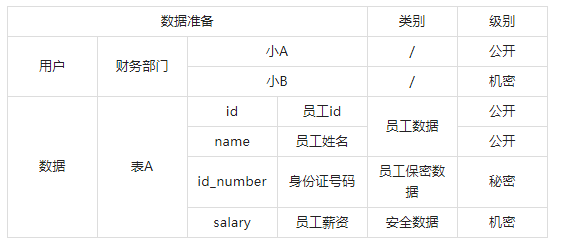
1.數據說明:
a) 級別定義
本案例采用三級模型:公開、秘密、機密。
b) 設置級別
為數據設置級別:

為用戶設置級別:

c) 新建脫敏規則

d) 員工保密數據類別設置脫敏策略

- 關聯數據:id_number
- 脫敏對象:小B
- 脫敏規則:身份證號碼脫敏
數據總結如下:
2.場景分析:
在數棲平臺安全管控下:
- 小A只能訪問id、name數據,當其訪問id_number、salary時,會被拒絕訪問;
- 小B可以訪問id、name、id_number、salary全部數據;但是當訪問id_number時看到的是被脫敏后的數據,例如41111119961127xxxx。
總結:
只有當用戶級別大于等于數據級別時,才被允許訪問。允許訪問之后,如果有脫敏策略,會進行脫敏處理。


