微調大模型的數據隱私可能泄露?
最近華科和清華的研究團隊聯合提出了一種成員推理攻擊方法,能夠有效地利用大模型強大的生成能力,通過自校正機制來檢測給定文本是否屬于大模型的微調數據集。
NeurIPS24論文 《Membership inference attacks against fine-tuned large language models via self-prompt calibration》,提出了一種基于自校正概率波動的成員推理攻擊算法SPV-MIA,首次在微調大模型場景下將攻擊準確度提高至90%以上。

成員推理攻擊(Membership Inference Attack)是一種常見的針對機器學習模型的隱私攻擊方法。該攻擊可以判斷某個特定的輸入數據是否是模型訓練數據集的一部分,從而導致訓練數據集相關的隱私被泄露。例如,該攻擊通過判斷某個用戶的信息是否被用于模型訓練來推斷該用戶是否使用了對應的服務。此外,該攻擊還可用于鑒別非授權訓練數據,為機器學習模型訓練集的版權鑒別提供了一個極具前景的解決方案。
盡管該攻擊在傳統機器學習領域,包括分類、分割、推薦等模型上已經取得了大量的研究進展并且發展迅速。然而針對大模型(Large Language Model,LLM)的成員推理攻擊方法尚未取得令人滿意的進展。由于大模型的大尺度數據集,高度泛化性等特征,限制了成員推理攻擊的準確性。
得益于大模型自身的強大的擬合和泛化能力,算法集成了一種自提示(Self-Prompt)方法,通過提示大模型自身生成在分布上近似訓練集的校正數據集,從而獲得更好的成員推理分數校正性能。此外,算法基于大模型的記憶性現象進一步設計了一種概率波動(Probabilistic Variation)成員推理攻擊分數,以保證攻擊算法在現實場景中穩定的鑒別性能。基于上述兩種方法,該攻擊算法實現了微調大模型場景下精確的成員推理攻擊,促進了未來針對大模型數據隱私及版權鑒別的相關研究。
現實場景中成員推理接近于隨機猜測
現有的針對語言模型的成員推理攻擊方法可以分為基于校正(Reference-based)和無校正(Reference-free)的兩種范式。其中無校正的成員推理攻擊假設訓練集中的文本數據具有更高的生成概率(即在目標語言模型上更低的Loss),因此無校正的攻擊范式可簡單地通過判斷樣本生成概率是否高于預設閾值來鑒別訓練集文本。

△Reference-free 無校正的成員推理攻擊流程圖
基于校正的成員推理攻擊認為部分常用文本可能存在過度表征(Over-representative)的特征,即天然傾向于具有更高的概率被生成。因此該攻擊范式使用了一種困難度校正(Difficulty Calibration)的方法,假設訓練集文本會在目標模型上取得相較于校正模型更高的生成概率,通過比較目標大模型和校正大模型之間的生成概率差異來篩選出生成概率相對較高的文本。
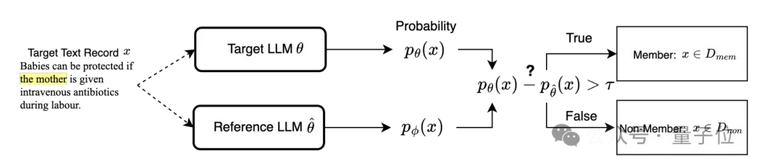
△Reference-based 基于校正的成員推理攻擊流程圖
然而,現有的兩種成員推理攻擊范式依賴于兩個在現實場景中無法成立的假設:1)可以獲得與訓練集具有相同數據分布的校正數據集,2)目標大型語言模型存在過擬合現象。 如下圖 (a)所示,我們分別使用與目標模型訓練集同分布、同領域、不相關的三個不同的校正數據集用于微調校正模型。 無校正的攻擊性能始終較低,并且與數據集來源無關。對于基于校正的攻擊,隨著校正數據集與目標數據集之間相似性的下降,攻擊性能呈現出災難性地下降。如下圖(b)所示,現有的兩種攻擊范式都僅能在呈現出過擬合現象的大模型中取得良好的攻擊性能。因此,現有的范式在現實場景中只能取得接近于隨機猜測的鑒別性能。
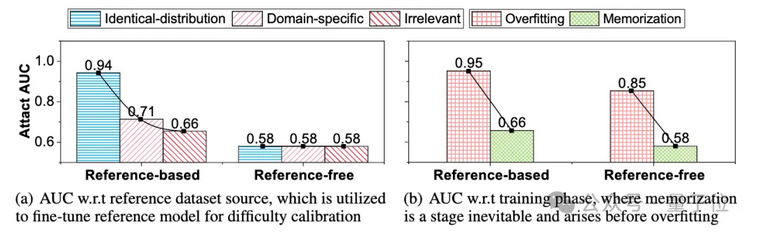
△現有攻擊范式在現實場景中的鑒別性能接近于隨機猜測
為了解決上述的兩點挑戰,我們提出了一種基于自校正概率波動的成員推斷攻擊(Self-calibrated Probabilistic Variation based Membership Inference Attack,SPV-MIA),由兩個相應模塊組成:1)大模型自校正機制:利用大模型本身生成高質量校正數據集,2)概率波動估計方法:提出概率波動指標刻畫大模型記憶現象特征,避免對模型過擬合的假設。
大模型自校正機制
在現實場景中,用于微調大模型的數據集通常具有極高的隱私性,因此從相同分布中采樣高質量的校正數據集成為了一個看似不可能的挑戰。
我們注意到大模型具有革命性的擬合和泛化能力,使它們能夠學習訓練集的數據分布,并生成大量富含創造力的文本。因此,大模型自身有潛力刻畫訓練數據的分布。
因此,我們考慮一種自提示方法,通過用少量單詞提示目標大模型自身,從目標大模型本身收集校正數據集。
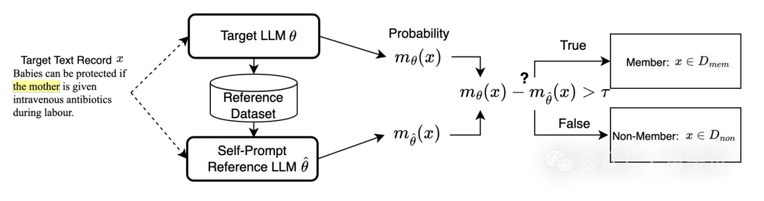
△大模型自校正機制方法流程圖
具體而言,我們首先從同一領域的公共數據集中收集一組長度為l的文本塊,其中領域可從目標大模型的任務中輕松推斷出來(例如,用于總結任務的大模型大概率在總結數據集上微調)。然后,我們將長度為l的每個文本塊用作提示文本,并請求目標大模型生成文本。
所有生成的文本可以構成一個大小為N的數據集,用于微調自提示校正模型 。因此,利用自提示校正模型校正的成員推理分數可寫為: 其中校正數據集從目標大模型中采樣得到: , and 分別是在目標模型和校正模型上評估得到的成員推理分數。
概率波動估計方法
現有的攻擊范式隱式假設了訓練集文本被生成的概率比非訓練集文本更高,而這一假設僅在過擬合模型中得到滿足。
然而現實場景中的微調大模型通常僅存在一定程度的記憶現象。盡管記憶與過擬合有關,但過擬合本身并不能完全解釋記憶的一些特性。記憶和過擬合之間的關鍵差異可以總結為以下三點:
發生時間:過擬合在驗證集困惑度(PPL)首次上升時開始,而記憶更早發生并貫穿訓練全程。
危害程度:過擬合通常,而記憶對某些任務(如QA)可能至關重要。
避免難度:記憶不可避免,即使早停止(Early-stopping)也無法消除,且減輕非預期記憶(如逐字記憶)極為困難。
因此,記憶現象更適合作為鑒別訓練集文本的信號。生成模型中的記憶會導致成員記錄比數據分布中的鄰近記錄具有更高的生成概率。

△過擬合與記憶現象在模型概率分布上的差異
這一原則可以與大模型共享,因為它們可以被視為文本生成模型。
因此,我們設計了一個更有前景的成員推理分數,通過確定該文本是否位于目標模型 概率分布上的局部最大值點: 其中 是由改寫模型采樣得到的一組對稱的文本對,這種改寫可被視為在文本高維表征空間上的微小擾動。本文中使用了Mask Filling Language Model (T5-base)分別在語義空間和表征空間上對目標文本進行擾動。
實驗結果:僅需1.000次查詢,達到超過90%的準確度
為了評估攻擊算法SPV-MIA的有效性,本研究在四個開源的大模型GPT-2.GPT-J,Falcon-7B,LLaMA-7B和三個不同領域的微調數據集Wikitext-103. AG News, XSum上進行實驗評估。
該研究采用了七種先進的基線算法作為對比:
無校正的攻擊方法(Loss Attack、Neighbour Attack、DetectGPT、Min-K%、Min-K%++)
基于校正的攻擊方法 (LiRA-Base、LiRA-Candidate)
對比實驗驗證了在上述大模型和微調數據集下所提方法相對于最先進基線方法的顯著性能提升,從AUC分數上看,提升幅度達30%。

△使用AUC分數的性能對比(加粗處為最佳性能,下劃線處為次佳性能)
從1%假陽率下的真陽率(TPR@1% FPR)來看,提升幅度高達260%,表明SPV-MIA可以在極低的誤報率情況下取得極高的召回率。
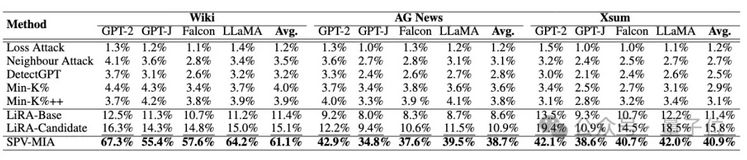
△使用1%假陽率下的真陽率的性能對比(加粗處為最佳性能,下劃線處為次佳性能)
此外,本文探究了基于校正的成員推理攻擊方法如何依賴于校正數據集的質量,并評估我們提出的方法是否能構建出高質量的校正數據集。本實驗評估了在同分布、同領域、不相關數據集和通過自提示機制構建的數據集上,基于校正的成員推理攻擊性能。實驗結果表明提出的自提示機制可以構建出近似于同分布的高質量數據集。
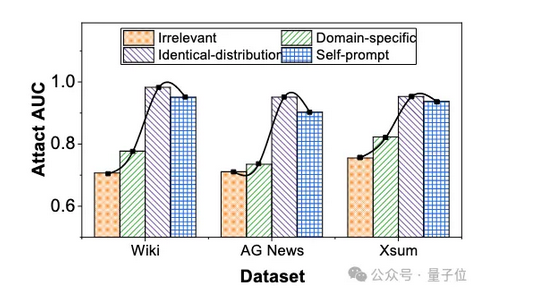
△使用不同校正數據集時成員推理攻擊的性能
在現實世界中,攻擊者可用的自提示文本來源通常受到實際部署環境的限制,有時甚至無法獲取特定領域的文本。并且自提示文本的規模通常受限于 大模型 API 的訪問頻率上限和可用自提示文本的數量。為了進一步探究SPV-MIA在復雜的實際場景下的魯棒性,本文從自提示文本來源,尺度,長度三個角度探究在極端情況下的成員推理攻擊性能。
實驗結果表明對于不同來源的提示文本,自提示方法對提示文本來源的依賴性低得令人難以置信。即使使用完全不相關的提示文本,攻擊性能也只會出現輕微下降(最多 3.6%)。因此自提示方法在不同先驗信息的攻擊者面前具有很強的通用性。
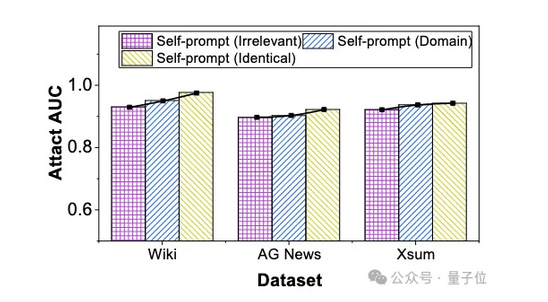
△SPV-MIA在不同來源自提示文本下的攻擊性能
并且自提示方法受查詢頻率的影響極低,只需要1.000次查詢即可達到接近于0.9的AUC分數。此外,當僅有8個tokens的自提示文本也可引導大模型生成高質量的校正模型。

△SPV-MIA在不同尺度、長度自提示文本下的攻擊性能
結論:
本文首先從兩個角度揭示了現有的成員推理攻擊在現實場景中無法對微調大模型造成有效的隱私泄露風險。為了解決這些問題,我們提出了一種基于自校正概率波動的成員推理攻擊(SPV-MIA),其中我們提出了一種自提示方法,實現了在實際場景中從大型語言模型中提取校正數據集,然后引入了一種基于記憶而非過擬合的更可靠的成員推理分數。我們進行了大量實驗證明了SPV-MIA相對于所有基線的優越性,并驗證了其在極端條件下的有效性。
論文鏈接:https://openreview.net/forum?id=PAWQvrForJ。
代碼鏈接:https://github.com/tsinghua-fib-lab/NeurIPS2024_SPV-MIA。


