大型語言模型(LLMs)的飛速發展,正在為企業帶來前所未有的業務創新,但同時也帶來了一系列超出傳統網絡安全范疇的“新”威脅。攻擊者不再滿足于入侵服務器,而是通過惡意輸入來操縱模型行為、竊取模型數據甚至損害模型本身,這些新威脅使得為大模型構建一個強大的安全防護體系,成為企業在AI時代下的當務之急。那么,國內廠商是如何應對這些“新”威脅,我們又該如何防御呢?
一、大模型安全威脅風險模型
為有效防御AI系統,尤其是大模型,首先需了解攻擊者利用其脆弱性的方式(攻擊模型),以及這些攻擊可能導致的危害(威脅模型),是制定防護策略的基礎。國際上已經形成了針對大模型風險的框架,為大模型安全防護提供基礎。其中
1)MITREATLAS(人工智能系統對抗威脅框架)是針對AI系統攻擊的系統化知識庫和框架,將攻擊者利用AI系統脆弱性的行為劃分為多個類別,每個類別下詳細列出具體攻擊技術,幫助企業從攻擊者視角理解AI系統的安全風險。
2)OWASP Top 10f or LLM包括了當前AI應用中最常見且影響顯著的問題。
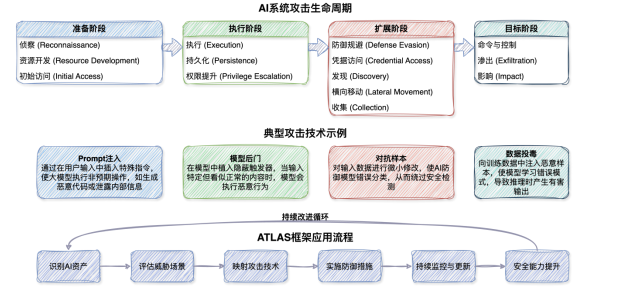
MITREATLASAI對抗威脅全景模型
基于MITREATLAS(人工智能系統對抗威脅框架)和OWASP Top 10f or LLM,安全牛結合國內廠商對AI安全的理解和實踐,總結了多層次的AI安全威脅模型框架,從業務層、數據層、應用層和基礎設施等多個維度,全面考量AI系統面臨的風險,為針對性防護提供依據。

安全牛的AI安全威脅風險框架
業務層安全風險:聚焦大模型應用直接面向用戶和業務時,對業務功能、內容可能造成的風險。其風險類型包括不安全輸出生成(如生成虛假信息、不合規內容),業務濫用(如利用大模型進行欺詐、惡意營銷),以及知識產權/版權侵犯(生成內容侵犯他人權益)。這些風險直接影響業務連續性和企業聲譽。
數據層安全風險:關注大模型訓練、推理過程中涉及數據的保密性、完整性和可用性風險。風險類型有訓練數據投毒(如攻擊者惡意篡改訓練數據),隱私泄露(如訓練數據或推理數據包含個人隱私信息被泄露),以及數據竊取(模型參數、訓練數據被非法獲取),推理攻擊(通過對模型輸出的分析反向推斷訓練數據)等。
應用層安全風險:主要涉及大模型應用本身、其API接口及組件相關的漏洞和被攻擊風險。風險類型包括提示詞注入(如通過惡意輸入操控模型行為),API漏洞(對大模型API進行未授權的訪問或惡意調用),代碼漏洞(大模型應用自身代碼的安全缺陷),惡意插件(不安全或惡意的外部插件集成),過度自主性(如模型未受限執行)以及模型拒絕服務(如API資源耗盡)。
基礎設施層安全風險:圍繞支撐大模型運行的底層硬件、軟件平臺、網絡環境和模型本身的安全展開。風險類型包括模型竊取(如非法獲取模型權限),模型篡改,供應鏈漏洞(如AI框架、庫、組件中的漏洞),基礎設施漏洞(如云平臺、服務器、容器漏洞),以及不安全代碼(如傳統組件安全缺陷)。
二、大模型安全威脅防護框架
安全牛從業務、數據、應用和基礎設施四個層面構建了AI安全風險防護框架,通過全面縱深的防御體系,應對大模型時代復雜多變的安全威脅,為大模型安全提供全方位保障。
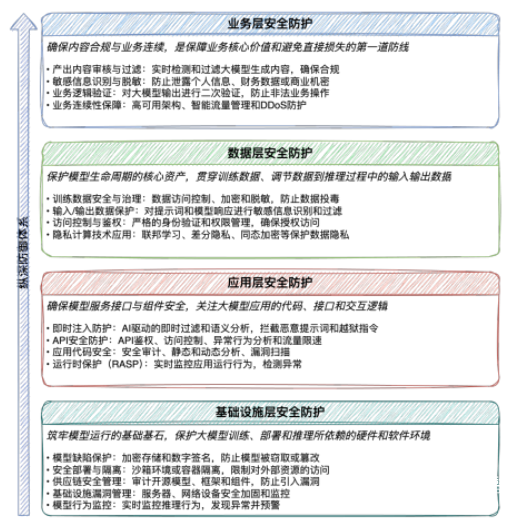
人工智能安全風險防護框架
1、業務層安全防護:確保內容合規與業務安全
業務層安全主要是關注大模型應用直接面向用戶和業務的輸出內容及服務可用性,是保障業務核心價值和避免直接損失的第一道防線。
輸出內容審核與過濾:部署基于人工智能的內容安全審查系統,對大模型生成的文本、圖片、音頻視頻進行實時檢測和過濾,識別敏感詞、有害信息,確保輸出內容符合法律法規和社會價值。知道創宇的大模型網關提供內容安全監測功能,能夠識別并攔截侵權、非法信息。
敏感信息識別與脫敏:對大模型輸出進行敏感信息識別,并進行自動化脫敏處理,防止無意或惡意泄露用戶個人身份信息(PII)、財務數據或企業商業機密。
業務邏輯驗證:結合業務規則對大模型的輸出進行二次驗證和人工復核,確保其不被用于非法的業務操作,例如,防止大模型輔助完成詐騙交易或規避內部流程。
業務連續性保障:實施高可用架構、智能流量管理和DDoS防護,確保大模型服務面臨大規模請求或資源緩慢攻擊時,仍能保持持續可用性,不影響核心業務運行。
國內廠商在大模型應用場景的業務層安全防護方面,采取了多種策略來確保內容合規與業務安全:
廠商案例
競恒智能主要側重于對大模型的安全評估,提供大模型內容安全防護服務,包括內容合規過濾服務、數據防泄漏保護服務等合規檢測。
默安科技的高交互大模型沙箱可以提供高仿真的大模型組件,支持Ollama、Dify、ClearML等主流AI開源框架,通過創建仿真的AI服務誘捕攻擊者,實現對攻擊者的追蹤溯源和反制,保護人工智能數字資產
奇安信的大模型衛士(QAX GPT-Guard)AI鑒定平臺可實現對大模型輸入輸出內容的深度檢測與智能攔截。識別并攔截涉政、賭博、色情、違法犯罪等違規內容,進行敏感信息識別與脫敏,并能防御提示詞注入和越獄攻擊,從而保障業務邏輯不被惡意操控。
瑞數信息的WAAP for LLM超融合解決方案加強了針對提示詞注入攻擊、信息泄漏風險以及API攻擊的檢測和防護。能夠實時審查模型輸出以阻斷敏感信息泄露并滿足合規要求,利用NLP處理和語義分析來防護提示詞注入攻擊。
云弈科技能夠提供對大模型Web應用的業務連續性保障和輸出內容完整性保護。
知道創宇的創宇大模型網關能夠監測并攔截敏感輸入輸出內容(如身份證、手機號等隱私數據和企業機密),阻斷涉密信息傳播,并提供提示詞注入和模型越獄防護以保障業務邏輯不被操控。此外還提供DDoS/CC攻擊防疫和熔斷保護機制,以及多模型切換/重試功能,全面保障大模型服務的業務連續性。
2、數據層安全防護:保護模型生命周期的核心資產
數據安全主要是關注貫穿大模型的整個生命周期,從訓練數據、調節數據到推理過程中的輸入輸出數據,任何中間的泄露或篡改都可能帶來嚴重的后果。
訓練數據安全與治理:實施嚴格的數據訪問控制、數據加密和數據脫敏技術,確保訓練數據的機密性和完整性。在數據進入訓練流程前,進行質量驗證和不良數據檢測,利用人工智能或統計方法識別并清除可能導致模型偏差或后門行為的投毒數據。
輸入/輸出數據保護:對用戶輸入到模型的提示詞(提示詞)和模型的生成響應進行敏感信息識別、過濾和脫敏。例如,阻止用戶在提示中輸入個人敏感信息,或防止模型在回復中無意泄露訓練數據中的PII。
訪問控制與鑒權:對模型API和云端數據存儲(如訓練數據集、模型權重存儲)進行嚴格的身份驗證和權限管理,確保只有授權用戶和應用程序才能訪問敏感數據。
隱私計算技術應用:探索和應用聯邦學習、差分隱私、同態加密等技術,在保護數據隱私的同時進行模型訓練和數據分析,尤其適用于多方協作訓練或處理高度敏感數據。
廠商案例
奇安信的大模型衛士提供全面的數據層安全防護,能夠對大模型訓練數據進行脫敏、加密和審計,還能實時識別、過濾和脫敏大模型輸入輸出的敏感內容(如個人信息、商業機密),并提供基于實名賬號的訪問控制與鑒權,保障模型API和數據存儲的安全。
瑞數信息的WAAP for LLM提供數據投毒防護和訓練前敏感數據清理,支持大模型敏感信息檢測和脫敏,并且可通過API防護和一次性令牌機制,有效確保大模型API的訪問安全,防止未經授權的訪問與濫用。
知道創宇的大模型網關能夠對訓練數據集進行清洗、提煉和分析,并能監測并攔截大模型輸入輸出的敏感內容,包括個人信息和商業數據,此外,通過路由管理和令牌分發,可對大模型API訪問進行精細化授權與控制,并屏蔽外部大模型訪問地址以防數據泄露。
3、應用層安全防護:模型服務接口與組件安全
應用安全主要是關注大模型應用本身的代碼、接口、集成組件以及與模型的交互邏輯,確保其不會被傳統或新型攻擊利用。
即時注入防護:部署基于AI的即時過濾和語義分析技術,在用戶輸入到達模型前進行實時檢測。利用深度學習和NLP技術識別并攔截惡意提示詞、越獄指令或數據泄露嘗試。
API安全防護:嚴格實施的API安全網關,對大模型服務接口進行API鑒權、訪問控制、異常行為分析和流量限速。默安科技的大模型在API安全中的應用強調能力“理解API行為、識別異常”,識別異常API調用和業務邏輯漏洞。
應用代碼安全:對大模型應用的代碼進行安全審計、靜態和動態分析(SAST/DAST/IAST)、漏洞掃描,確保代碼本身無漏洞,防止攻擊者利用應用代碼漏洞滲透。
運行時保護:部署RASP(運行時應用自保護)或IAST(交互式應用安全測試)工具,實時監控大模型應用的運行行為和內部交互,檢測非預期行為。
廠商案例
奇安信的大模型衛士提供全面的應用層安全防護。能夠基于AI和語義分析技術對用戶輸入的提示詞進行檢測與防護,攔截惡意提示詞、越獄指令和數據泄露嘗試。可以實施API鑒權、訪問控制、高危操作管控、全鏈路審計與溯源,并能對大模型API訪問進行精細化授權控制。
瑞數信息的WAAP for LLM能夠識別并攔截惡意提示詞、越獄指令等,可防止API濫用和批量攻擊,并可對主流大模型框架的供應鏈組件進行漏洞檢測、驗證和防護。另外,還可以利用動態混淆技術保護LLM應用代碼和傳輸數據。
知道創宇的大模型網關提供提示詞注入防護和模型越獄防護,并進行關鍵詞和價值觀內容監測。通過統一接入管理、基于微隔離的權限管控和Token配額管理和限流,對大模型API訪問進行精細化授權與控制。并提供全鏈路可觀測能力,包括LLM調用、Token消費和資源使用統計,以及實時預警模型、內容和流量異常,并可追溯對話和訪問日志以實現安全審計。
4、基礎設施層安全防護:筑牢模型運行的基礎基石
設施基礎安全主要關注大模型訓練、部署和推理所依賴的硬件、軟件平臺、網絡環境以及模型本身的存儲和缺陷。
模型缺陷保護:對模型的權限重、參數和結構進行加密存儲和數字簽名,并在加載和運行前進行缺陷校驗,防止模型被竊取或篡改。
安全部署與隔離:在安全的沙箱環境或容器中運行大模型,與其他業務系統進行嚴格隔離,限制其對外部資源的訪問權限。
供應鏈安全管理:對所有引入的開源模型、框架、庫和組件嚴格進行安全審計、漏洞掃描和供應鏈風險評估,防止引入不良或帶漏洞的組件。
基礎設施漏洞管理與防護:對服務器、網絡、網絡設備、容器平臺等進行專題的漏洞管理和安全隊列,部署傳統的防火墻、入侵檢測、DDoS防護等措施。
模型行為監控:實時監控大模型的推理行為和資源消耗,通過AI分析其行為模式,發現異常,預警模型被攻擊或補償。
廠商案例
奇安信的大模型衛士在基礎設施層提供全面的安全部署與隔離(包括安全代理網關對大模型運行狀態的防護和權限管控)以及供應鏈安全管理,可對主流大模型框架的組件進行漏洞檢測與防護。
瑞數信息的WAAP for LLM可以實現安全部署與隔離,支持對主流大模型框架供應鏈組件的漏洞檢測以及API安全掃描和AI基礎設施安全評估,并具備Bot防護、WAF、CC、DDoS防護等能力。
知道創宇的大模型網關在基礎設施層支持統一接入管理和基于微隔離的權限管控,采用代理模式接入,提供網絡安全防護(包括Web攻擊防護、DDoS防護),可實時檢測分析流量,識別并封禁惡意IP,實現內外部威脅雙向阻斷。
大模型安全,不僅是技術上的挑戰,更是企業在AI時代下的核心競爭力。構建一套全面的多層防護體系,才能確保AI創新安全、可靠地落地。


