- 其一是IT系統(tǒng)運行類問題和故障的分析和解決;
- 其二是面對復雜業(yè)務問題時候?qū)⑵滢D化為技術解決方案能力。
在前面我講思維類文章的時候就專門談到IT人員應該關注自己思維能力的提升,這個思維能力實際上包括了分析和認知事物,獨立的問題分析和解決兩個層面的內(nèi)容。
- 對于第一個層面在IT領域更多的就是架構設計的能力,將現(xiàn)實的業(yè)務需求和場景轉化為抽象的架構設計語言和架構模型的能力;
- 而第二個層面在IT領域里面即是面對問題或故障的時候進行問題分析診斷,假設和驗證,快速解決的能力。
而對我們當前很多IT人員來說,實際上兩個方面的能力都欠缺,既不能獨立的進行整體架構設計,對負責的業(yè)務進行自頂向下,分而治之的建模和設計。也不能在面對生產(chǎn)環(huán)境關鍵故障或問題的時候快速定位,并找到根源快速解決。而是將自己大量的時間花費在重復的事務性工作上,花費在對各類新技術的狂熱追求上。
實際上自己也從不反對保持對新技術的學習興趣。但是任何新技術,如果你實際的工作環(huán)境沒有實踐的機會,那么大量新技術下應該出現(xiàn)的類似性能,安全,可靠性等問題你都無法真正得到實踐驗證和解決。
在這種情況下對新技術也只能夠停留在理論階段而無太大意義。
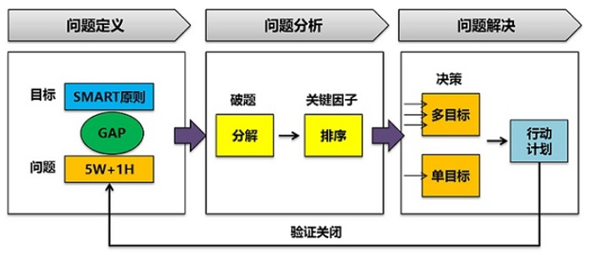
對于問題分析和解決的核心邏輯,可以先參考我前面發(fā)布的文章:《問題分析和解決邏輯-麥肯錫七步成詩僅是開始》(http://blog.sina.com.cn/s/blog_493a84550102z8l9.html) 在前面這篇文章里面,結合麥肯錫問題分析七步法,對問題分析核心邏輯進行了詳細的描述。
一、技術問題解決的關鍵點
我寫過不少的關于技術問題分析和診斷的文章,這些問題基本也是來源于真實的項目實踐。
即使到現(xiàn)在有些問題也沒有完全得到定位和最終解決,包括我們找了Oracle專家和顧問,也不是說馬上就能夠滿足我們解決掉該技術問題。
簡單來說,如果一個技術問題,你能夠直接快速的根據(jù)異常或問題關鍵字在網(wǎng)上搜索到相關的答案,這種問題都談不上真正有挑戰(zhàn)的技術問題。
對于技術問題的解決,基于前面實踐的問題定位、分析和解決的思路,我還是想談下在解決技術問題中的一些關鍵點和思考邏輯方面的內(nèi)容。
1、個人前期大量實踐經(jīng)驗的積累
這點相當重要,任何知識庫,搜索都代替不了個人已有的知識經(jīng)驗積累。

為什么說工作經(jīng)驗很值錢?
往往就是因為你在一個專業(yè)領域有大量實踐積累,大量問題分析解決經(jīng)驗積累。這些經(jīng)驗可以幫助你在遇到問題的時候快速地對問題進行預判和定位,包括提出最可能的假設路徑。
當前解決問題,很多都是非結構化解決問題方法,即是優(yōu)先提出最可能的假設,然后再去驗證假設是否能夠真正解決問題。
那么有經(jīng)驗的人往往就最容易提出最可能的假設路徑,而減少對各種不可能彎路的嘗試。一個問題本身有A到E五個獨立假設路徑,而最可能路徑是A,你解決問題速度慢的原因往往就是你最后才假設和嘗試到A路徑并解決問題,而有經(jīng)驗的人往往一開始就選擇了假設A進行驗證。
要積累這種經(jīng)驗,必須在問題解決后及時復盤,將其抽象為經(jīng)驗和方法論。
問題定位的重點就是縮小范圍和確定邊界。一個問題出現(xiàn)之后最重要的就是快速的定位。
比如一個業(yè)務系統(tǒng)查詢故障,要快速的定位是基礎設施資源的問題,還是數(shù)據(jù)庫和中間件的問題,還是說程序的問題。
如果是程序的問題,又需要馬上定位到究竟是前端的問題,還是邏輯層的問題或數(shù)據(jù)庫的問題。
只有快速的確定邊界和定位問題,才能夠有針對性的去解決問題。任何問題的定位都是追溯到引發(fā)問題的根源,而不是解決問題的表象,類似頭痛醫(yī)頭腳痛醫(yī)腳。
那么如何縮小范圍和快速的確定邊界?

比如我們假設一個最簡單的場景:問題的產(chǎn)生經(jīng)歷了A-》B的兩個過程。那么如何快速的確定問題是在A階段產(chǎn)生的還是在B階段產(chǎn)生的呢?
對于這個問題,我們有如下的問題定位方法和思路可以參考和借鑒:
- 替換法:比如將A替換為A1,如果問題消失,那么說明問題出在A階段;
- 斷點法:在A和B之間設置斷點監(jiān)控輸出,判斷A輸出是否正常;
- 假設法:假設A階段有問題,對A階段的參數(shù)進行調(diào)整,觀察問題是否解決。
當然還有其他很多的問題定位方法,但是對于所有問題定位和確定邊界的方法中,最有效的仍然是類似于快速查找中的二分法,通過二分法可以快速的幫助我們縮小范圍和定位問題。
我們進一步對上面邏輯舉例說明,比如一個軟件應用出現(xiàn)Bug的場景,如下圖:

可以看到看到要分析和定位Bug為何困難?
引入問題既可能是我們的輸入出現(xiàn)錯誤,我們面對的軟硬件環(huán)境運行狀態(tài)有問題,也可能是我們實際程序處理構成出現(xiàn)問題。
即使你定位到程序處理問題,那么還可能是邏輯層,數(shù)據(jù)訪問層或數(shù)據(jù)庫多個點導致的問題。
2、善用搜索引擎

要明白,任何你遇到過的技術問題,往往都有前人遇到過,踩過坑,并總結和分享到互聯(lián)網(wǎng)上面。因此善用互聯(lián)網(wǎng)和搜索引擎,進行基于問題關鍵字的技術檢索仍然是解決技術問題的關鍵途徑。
即使搜索引擎沒有幫助我們解決最終的問題,往往也會幫助我們在搜索的過程中學習與該技術問題相關的很多知識。
要搜索,一個重點就是選擇搜索的關鍵字,對于關鍵字的選擇沒有一次就選擇準確的話,自己就要多次嘗試和迭代,直到能夠準確的描述問題為止,同時在搜索的過程中搜索的答案往往也可以幫助你進一步的細化關鍵字。
比如對于系統(tǒng)運行故障或問題,對于關鍵字的描述,應該包括:
- 從數(shù)據(jù)庫,中間件和業(yè)務系統(tǒng)錯誤日志中提取關鍵字信息;
- 從你產(chǎn)生問題的環(huán)境,背景,場景中增加縮小檢索范圍的關鍵字信息;
- 從搜索到的網(wǎng)頁中挖掘更加有意義的描述類似問題的關鍵字信息。
同時對于搜索而言,特別是技術問題的搜索,有官方知識庫的要優(yōu)先搜索官方的知識庫:比如對于Oracle產(chǎn)品相關的技術問題,我們也會先搜索Oracle官方的Support網(wǎng)站,同時搜索類似StackOverFlow網(wǎng)站,這些網(wǎng)站往往有更加全部的技術問題解決文章。
搜索技術文章,那么國外的技術網(wǎng)站相對來說更加全面,而對于百度這塊相對弱,很多國外技術網(wǎng)站內(nèi)容甚至都搜索不到,這時候可以嘗試Google或Bing搜索。
3、技術問題解決和復盤
在前期我們實施Oracle SOA項目的時候,遇到了將服務封裝和注冊接入到OSB后,客戶端消費和調(diào)用服務出現(xiàn)消息報文內(nèi)容被截斷的問題。
由于該問題出現(xiàn)概率不高,并且消費端系統(tǒng)本身有重試機制,也暫時不影響到具體的OSB服務運行和使用。雖然到現(xiàn)在為止,造成該問題的原因究竟是客戶端服務器配置,負載均衡,網(wǎng)絡,報文本身,OSB套件本身的Bug缺陷等哪方面還沒有最終確認,但是整個問題排查和分析過程還是有意義的。
在問題排查和分析過程中,對于各類超時時間的含義,OSB的一些關鍵配置,報文解析,Http Post報文發(fā)送長短連接,Tomcat的一些配置都進行了了解,同時通過該問題的分析,也發(fā)現(xiàn)了在技術問題分析過程中的一些問題,供后面在分析問題中借鑒和參考。
4、確定問題邊界始終是最重要的
客戶端發(fā)送報文到服務器端接收報文,當前現(xiàn)象是客戶端Log日志報文是完整的,而OSB上Log的日志報文不完整。
那么究竟是客戶端,服務端,還是網(wǎng)絡傳輸過程中出現(xiàn)的問題?這個問題邊界的確定相當重要。
實際上在幾天的問題分析和排查中對于問題邊界一直沒有最終確認,導致問題也一直沒有很肯定的得到定位究竟在哪里,也導致最終問題沒有得到明確的解決和排查。
比如上面說的消息報文不完整這個問題,要確定邊界實際上常規(guī)思路也就兩種,
- 一種就是修改程序代碼進行更加詳細的日志記錄;
- 另外一種就是增加Trace監(jiān)控。
比如該問題可以在客戶端進行Http或TCP Trace,同時在服務器端也進行Http TCP Trace,通過兩邊的Trace信息才能夠最終確定問題的邊界在哪里。
但是在生產(chǎn)環(huán)境很難這樣去做,
- 一個是接口服務調(diào)用并發(fā)量大導致Trace日志的量也巨大,而且不止這一個接口服務在調(diào)用;
- 一個是協(xié)調(diào)的需要配合的資源也太多,很難去聯(lián)合排查和跟蹤。
5、問題復現(xiàn)很重要
故障的復現(xiàn)是我們分析和定位問題的一個基礎,問題如果隨機偶然發(fā)生往往是最難解決的。當你面對問題的時候,你需要定位,那就需要問題能夠復現(xiàn)才方便不斷地去Debug或Trace。

在該問題的解決過程中,由于該異常是偶然出現(xiàn),不定時而且是沒有規(guī)律出現(xiàn),所以也給我們排查問題造成了很大的麻煩。
雖然在問題排查過程中,我將出現(xiàn)問題的異常日志,和前后正常的實例都進行了導出分析,對出現(xiàn)問題的服務器Server節(jié)點、調(diào)用方、調(diào)用時間段都進行了分析,但是沒有明顯的發(fā)現(xiàn)出現(xiàn)問題的規(guī)律究竟在哪里。
同時該問題具有很高的隨機性,往往是第一次調(diào)用不成功,但是同樣的報文在第二次或第三次就調(diào)用成功,同時每次對于報文的截斷長度都不相同。這導致很難分析具體什么場景下調(diào)用不成功。
即由于問題不能在特定的輸入條件下重現(xiàn),導致我們很難對問題進行進一步的分析和定位,也導致我們很難去進行特定的跟蹤和邊界確定。同時也很難在測試環(huán)境對該問題進行進一步的分析,和各種參數(shù)條件修改后的測試和驗證。
即由于問題不能在特定的輸入條件下重現(xiàn),導致我們很難對問題進行進一步的分析和定位,也導致我們很難去進行特定的跟蹤和邊界確定。同時也很難在測試環(huán)境對該問題進行進一步的分析,和各種參數(shù)條件修改后的測試和驗證。
以上都導致問題很難快速定位和分析,只能夠大范圍的場景+異常的關鍵字搜索,然后搜索到相關的可能解決方案后,一個個的去嘗試看是否能夠解決。
但是,這種方式帶來巨大的問題,即:
由于測試環(huán)境問題不復現(xiàn),我們無法在測試環(huán)境做這個事情。那么搜索到的解決方案驗證只能夠在生產(chǎn)環(huán)境做,但是生產(chǎn)環(huán)境根據(jù)規(guī)定是絕對不允許隨意去修改配置和調(diào)整參數(shù)的。
這也正是我們看到很多大型IT項目上線,往往會預留3個月左右的試運行期間的原因,在試運行期間生產(chǎn)環(huán)境的日常運維和配置修改不會嚴格受控管理,也方便及時分析和解決問題。
6、網(wǎng)上搜索很難搜索到完全一致的異常場景
由于項目采用的Oracle SOA Suite 12c套件產(chǎn)品,當前在國內(nèi)并沒有大范圍的應用,所以如果用百度搜索基本搜索不到有用信息,改用Google或Bing很多信息也無法搜索到。
因此在該問題的排查過程中,我們基本都在Oracle Support網(wǎng)站進行了所有相關知識點的排查,同時選擇各類關鍵字進行搜索引擎的搜索,其中包括了:
- Weblogic Tomcat Post Timeout KeepAliveOSB-;
- 長連接 超時 OSB-382030;
- Failed to parse XML text等。
但是并沒有搜索到完全一致的場景。
對于一個最相似的關于Failed to parse XML document的場景,我們進行了相關的調(diào)整,即將KeepAlive設置為False,同時對Post Timeout設置為120秒,但是仍然出現(xiàn)在120秒超時時間到達后任何沒有Post到完整的請求而導致超時的問題。
由于無法搜索到完全類似的場景,也導致我們很難根據(jù)網(wǎng)上給出的方法進行進一步測試和驗證。并且Oracle顧問對于該問題也只能給出進行Tcp Trace的無用建議。
7、關鍵基礎技術知識缺乏,導致問題分析和提出假設不合理
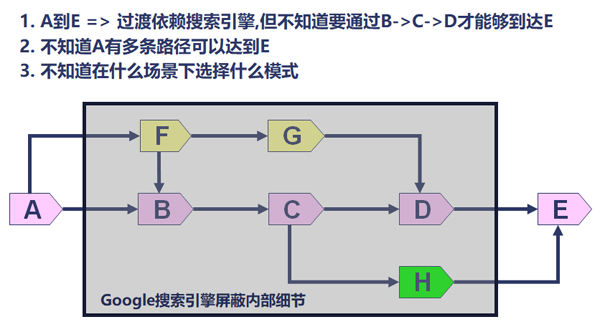
在原來問題的分析和解決中,由于搜索引擎往往會給出完全類似的場景,我們只需要根據(jù)搜索引擎給出的排查思路對問題進行排查即可。
因此解決起來效率很高,對于具體底層原理性的內(nèi)容我們并不需要掌握和了解,只需要能夠選擇合適的關鍵字,通過搜索引擎搜索到最合適的內(nèi)容然后進行排查即可。
但是這次問題,特殊點就在于搜索引擎根本無法給出完全類似的文章。這就導致需要基于問題提出各種合理的假設,并對假設進行逐一驗證。
那么如何提出合理的假設?
這里就涉及到對于TCP底層協(xié)議,各個超時值的含義和原理,Tomcat Server的參數(shù)配置,OSB代理服務的解析過程,Weblogic的關鍵參數(shù)配置和含義,負載均衡策略,乃至Docker容器和IP映射等很多內(nèi)容都有技術積累才可能提出最合理的思路。
比如在排查過程中,我會想到是否需要將Tomcat 的MaxPostSize值調(diào)大的假設,但是該異常是Tomcat向Weblogic Server進行Post請求發(fā)送數(shù)據(jù),對于Tomcat 的MaxPostSize根本不會影響到這個Post請求,而只有Weblogic上的Post Size才會有影響。這個假設本身就不合理。而要快速的判斷這些假設不合理,你就必須提前有這些關鍵的基礎技術知識和背景積累。
包括對于Keep Alive長連接,Keep Alive的Time out超時時間設置是否會對該服務異常調(diào)用操作影響,實際上由于對Keep Alive長連接和各類Timeout的具體含義理解的并不深入,也使得很難判定究竟是否有影響,也只能是注意嘗試去排除可能性,這些也都導致了很難快速的定位出問題根源究竟在哪里。
8、涉及到外圍干系人協(xié)同時問題解決困難
這個也是解決服務接口問題的一個關鍵影響。對于接口服務運行問題,往往涉及到業(yè)務系統(tǒng)消費方,業(yè)務系統(tǒng)提供方,OSB服務總線,網(wǎng)絡,負載均衡設備等多個相關因素和廠商。
對于一個問題的排查往往需要協(xié)調(diào)多方的資源在約定的時間相互配合才能夠完成,這些都直接導致排查難度很大,很難依靠個人一方力量就完成。
在原來類似大項目實施過程中,也經(jīng)常會遇到這些接口問題的分析和排查,往往也都是問題造成嚴重影響后,各方才會真正重視該問題,并各自協(xié)調(diào)資源形成聯(lián)合的問題排查團隊進行問題分析和排查,最終才能夠解決問題。
雖然截止現(xiàn)在問題沒有得到最終解決,但是整個分析過程仍然有意義,特進行本文總結。
二、問題復盤-文件句柄打開過多
在前面已經(jīng)談到,問題分析解決后需要及時復盤,對于問題復盤不是簡單的問題解決總結,而是對整個問題分析思考過程進行梳理,包括在問題解決中究竟踩了哪些坑,走了哪些彎路,這些經(jīng)驗教訓對后續(xù)問題的解決有哪些參考意義等。
問題描述:服務器響應很慢,服務調(diào)用出現(xiàn)超時,接著查詢相關的錯誤日志信息。在錯誤日志信息里面包括了IO Exception的too many open files信息,也包括了socket receive time out的socket連接超時的信息。
1、應用服務器監(jiān)控情況檢查
在拿到這個問題后,由于原來也出現(xiàn)過服務響應慢和調(diào)用超時的問題,所以首先排查的是應用服務器本身的健康狀況,因此開始用jstat檢查服務器本身的cpu和內(nèi)存的使用情況,經(jīng)過檢查服務器本身完全正常。
2、數(shù)據(jù)庫連接池和線程池檢查
在檢查這個后接著檢查數(shù)據(jù)庫連接池和線程池的情況,經(jīng)過檢查雖然有排隊情況,但是連接池本身都還有大量剩余,也不存在連接池超了的情況。
3、錯誤日志檢查
在這個檢查完后回到問題錯誤日志,由于當前有兩個錯誤,即:
- 問題A文件打開過多,問題B服務連接超時,那現(xiàn)在有一個關鍵問題就是究竟是A問題導致了問題B,還是B問題導致了問題A,還是A和B本身就是在同一時間導致的兩個本身不相關的問題,在這個時候其實并沒有完全肯定的結論。
這就導致我們需要從兩條問題路徑去查找問題的根源,然后再進行總結和收斂。
要知道對于問題B連接超時,Oracle官方的Support網(wǎng)站知識庫包括問題解決的6到7個場景的排查,整個排除起來是相當困難的。
而且該問題是老服務器出現(xiàn)的新問題,而不是完全新增加服務器出現(xiàn)的問題。那必須就要考慮是否和新部署和上線的服務和應用有關系。
4、回溯近期所做的代碼變更
現(xiàn)在回到文件打開數(shù)過多的問題,經(jīng)過基本問題查看,發(fā)現(xiàn)的就是文件句柄打開太多,那么我們要做的就是對新增加的修改和變更進行查看,還是否存在文件句柄沒有關閉的情況。
5、異常-》文件打開太多-》進一步定位是哪些文件
經(jīng)過代碼的Review我們沒有發(fā)現(xiàn)這種情況。那接著很自然就是要進一步去定位和分析究竟哪些文件句柄打開沒有關閉?
而查這個問題的方法是lsof進行l(wèi)og數(shù)據(jù),有發(fā)現(xiàn)我們的hpunix小型機居然這個命令無法使用,沒有辦法我們先單純的調(diào)高的最大文件打開數(shù)現(xiàn)狀但是問題依然存在。
注意在這個時候我們停在這里了,沒有進一步去想如何解決這個問題,而轉到去分析服務超時問題。
注:當我們在進行問題分析診斷的時候,選擇的沒有問題的標準解決路徑,不要輕易因為阻礙而放棄,你會發(fā)現(xiàn)最終你又會回到這個關鍵路徑上。
在面對服務超時的問題的時候,我們又走了彎路,即直接根據(jù)metalink排查方式對各個問題場景進行分析和排除,對中間件的參數(shù)和設置進行了大量的修改,但是最終該問題還是沒有解決。
之所以說走了彎路的原因主要在于沒有很好地去分析當前服務器出現(xiàn)服務超時的具體原因,對應當前場景沒有做具體的分析。
6、進一步分析問題產(chǎn)生的場景和邊界
所以后續(xù)還是回到當前場景的分析,在當前服務器我們新增加部署了哪些服務,這些服務是否需要逐個進行排除,我們實際的服務運行是都超時,還是個別服務超時?這個服務超時究竟是發(fā)生在哪邊?具體的邊界在哪里這些問題都需要進一步搞清楚才能有后續(xù)行動。
1)邊界確認:不是所有服務調(diào)用都超時
第一個情況就是不是所有的服務都出現(xiàn)超時的問題,主要出現(xiàn)超時的服務都是某種類型的服務,然后我們對超時的服務和服務超時日志進行排除,包括具體的防火墻設置,長事務運行的服務本身等。
2)邊界確認:不止是新增加的服務超時,老服務也超時
現(xiàn)超時的服務并不是都是新增加的服務,也包括了已經(jīng)有的老的服務運行,確實是一個很奇怪的現(xiàn)象。在服務超時設置參數(shù)都進行調(diào)整后,繼續(xù)觀察服務器的健康狀況和錯誤日志記錄,發(fā)現(xiàn)繼續(xù)出現(xiàn)too many files open的錯誤。
在這個時候發(fā)現(xiàn)還是得回到too many file open這個異常日志上進行進一步的分析原因。
7、回歸到在hpunix上安裝lsof組件
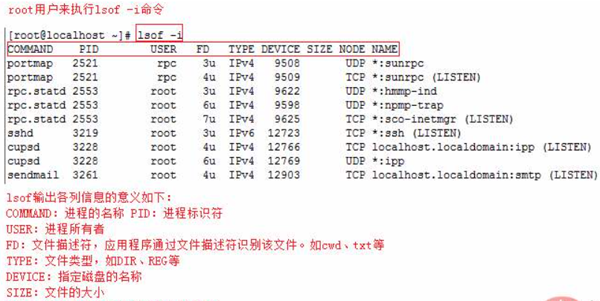
要詳細分析必須有詳細的log日志以進行定位,到這個時候發(fā)現(xiàn)還是必須首先得安裝上lsof組件,接著就是查找資料重新在hpunix上安裝上lsof組件,組件安裝后進行詳細的lsof日志。
然后每1個小時左右新取一次lsof的數(shù)據(jù),通過對lsof數(shù)據(jù)的分析發(fā)現(xiàn)確實存在文件句柄不斷的增加而無法釋放的情況。
到了這一步后出現(xiàn)兩個小問題分支:
- 一個是對lsof數(shù)據(jù)發(fā)現(xiàn)對oracle數(shù)據(jù)庫連接使用的是1524后門端口,開始懷疑是這個端口使用有問題,但是后面否定了該假設;
- 那還是回到文件句柄問題上。
那這個問題的關鍵就是:究竟是哪些文件句柄不算在增加?
后面對lsof日志進行詳細分析,發(fā)現(xiàn)了總是60多個文件句柄不斷的在增加和打開,這些文件句柄反復打開多次,而且file inode值也是一樣的,到了這個時候關鍵的想法就是如何通過file inode查找到具體是哪些文件?
因為在實際的日志記錄中只有文件的路徑而沒有文件的名稱,一時在這個地方停滯。
到了這一步,沒有辦法,要做的還是詳細的研究lsof日志中的每一個字段的具體含義,找尋如何通過file inode找尋到具體文件的方法。
那先想到的就是文件系統(tǒng)中的文件本身是否有inode的說法,后面看到通過ls命令是可以查找到每個文件的文件句柄的。那自然我們可以對所有的文件通過ls查找并導出inode信息,然后和lsof中的文件句柄進行比對找到具體的文件。
根據(jù)該思路我們到處所有文件屬性信息進行比對,最終找到文件句柄不斷打開的文件是哪些。
一看到這些文件在不斷的打開,問題根源點基本就找到了,這些文件都是和我們的底層一個服務組件有關系的,那么接著看打開這些文件的方法,在打開這些文件的使用完成后釋放及時進行了資源的釋放。
8、源碼最終定位-saxReader類文件處理
經(jīng)過源代碼分析,發(fā)現(xiàn)了具體的問題就是文件不斷的打開,但是不是手工對文件句柄進行關閉。
但是我們的生產(chǎn)環(huán)境為何沒有出現(xiàn)通用的問題,這個是和saxReader類處理文件的方法是有關系的,saxReader類對文件是會進行關閉,但是具體時間我們并不清楚。
那生產(chǎn)環(huán)境為何沒有出現(xiàn)同樣的問題,是否是在fgc的時候會進行回收,這個也只是一個假設,暫時沒有做進一步的驗證,但是至少分析出對于文件的大量持續(xù)打開肯定是需要修改的。
在對代碼進行修改后重新部署,部署完成后進行觀察,沒有再進一步出現(xiàn)過too many files的文件IO異常。但是接著還是繼續(xù)出現(xiàn)一些服務超時異常。
9、問題因果要分清
但是任何服務超時異常都不會再引起too many files打開的異常,突然發(fā)現(xiàn)剛開始出現(xiàn)的問題A和問題B,實質(zhì)是反應出了我們當前應用存在兩個偏獨立的問題,雖然兩個問題間可能存在相互影響,但是問題本身偏獨立,都有各自的問題導致根源。
在進一步分析服務超時問題的時候,我們對服務調(diào)用調(diào)用詳細日志數(shù)據(jù)進行分析,發(fā)現(xiàn)大多數(shù)服務都是正常的,而僅僅是個別服務出現(xiàn)了服務調(diào)用超時的問題,那么接著還是對單獨的個別服務進行原因查找。
由于是個別服務的問題,我們完全可以懷疑是服務提供方系統(tǒng)出現(xiàn)了問題,那么就需要對服務提供方提供的服務能力進行原因定位和查找,最終找到了一個原因即對方的操作導致了對方數(shù)據(jù)庫出現(xiàn)死鎖而服務一直處于等待和鎖定狀態(tài),基于這個假設我們后續(xù)進行了證實確實是該原因。
到這一步基本所有的問題根源點和原因都基本確認清楚,通過該次問題定位,分析和解決,進一步完善了對應服務應用性能和問題定位的分析和解決方法,從CPU內(nèi)存再到IO,從服務異常日志再到服務詳細的調(diào)用日志信息,基本形成了一個完整的診斷方法。
三、問題復盤-服務調(diào)用超時
最近跟蹤OSB服務運行超時,發(fā)現(xiàn)一個很奇怪的現(xiàn)場,即在調(diào)用業(yè)務系統(tǒng)的時候出現(xiàn)1500秒超時返回的情況。而在OSB本身做服務封裝設置的時候,我們會設置兩個時間,如下:
- Socket Read Time out : 該超時設置為600s;
- Connectoin Time out:連接超時設置為30s。
也就是說實際在OSB配置里面并沒有出現(xiàn)過1500秒超時的任何配置情況。
后面詢問業(yè)務系統(tǒng),得到的答復是業(yè)務系統(tǒng)那邊有5分鐘,即300s的超時設置。但是即使如此,也應該是返回300s的超時錯誤,而不是1500s。
一開始我們始終在分析,是否是300s超時,重試了5次,導致看到的最終超時設置是1500s,因此我們將OSB的所有配置參數(shù)又全部檢查了一遍,結果沒有檢查到任何的有5分鐘的超時配置項,同時也沒有檢查到有任何的重試次數(shù)是5次的檢查項。
在OSB業(yè)務服務配置的時候,確實可以配置重試,但是我們當前的設置為:
- 最大重試次數(shù)為 0;
- 是否支持應用程序重試,這個是true。
但是既然最大重試次數(shù)為0,即使后面的這個checkbox為true,也不應該去進行重試。
因為從調(diào)用其它的業(yè)務系統(tǒng)的接口服務返回情況來看,都沒有發(fā)生過相應的重試操作。同時后續(xù)在和業(yè)務系統(tǒng)測試的過程中,將該checkbox取消選擇,同樣會發(fā)生1500秒的錯誤,因此暫時確定和該參數(shù)關系并不大。
后面詳細查看日志,會發(fā)現(xiàn)整體過程為:
- 2018-10-24 11:25:38開啟調(diào)用
- Oct 24, 2018 11:35:49,172 AM GMT+08:00 報600s掛起
- Oct 24, 2018 11:50:46,140 AM GMT+08:00 報Connection Reset
- 在600s即到了我們設置的Read out timeout的實際,會報出如下異常信息:
- WatchRule: (log.severityString == 'Error') and ((log.messageId == 'WL-000337') or (log.messageId == 'BEA-000337'))
- WatchData: MESSAGE = [STUCK] ExecuteThread: '7' for queue: 'weblogic.kernel.Default (self-tuning)' has been busy for "610" seconds working on the request "Workmanager: SBDefaultResponseWorkManager, Version: 0, Scheduled=false, Started=true, Started time: 610222 ms
- ", which is more than the configured time (StuckThreadMaxTime) of "600" seconds in "server-failure-trigger". Stack trace:
- java.net.SocketInputStream.socketRead0(Native Method)
這個異常是和600s超時相關的一個異常信息,即Socket Read timeout,同時在報出這個異常信息后,該線程在60秒后又進行了一次重試,即:
- <[STUCK] ExecuteThread: '7' for queue: 'weblogic.kernel.Default (self-tuning)' has been busy for "670" seconds working on the request "Workmanager: SBDefaultResponseWorkManager, Version: 0, Scheduled=false, Started=true, Started time: 670227 ms
- ", which is more than the configured time (StuckThreadMaxTime) of "600" seconds in "server-failure-trigger". Stack trace:
而后續(xù)在日志中搜索不到線程7的相關記錄,同時在間隔900秒后出現(xiàn)Connection Reset的報錯。
- javax.ws.rs.ProcessingException: java.net.SocketException: Connection reset
- at org.glassfish.jersey.client.internal.HttpUrlConnector$3.run(HttpUrlConnector.
即初步分析很可能的原因是服務調(diào)用本身在5分鐘在業(yè)務系統(tǒng)端超時了,但是業(yè)務系統(tǒng)端沒有對連接進行處理或關閉,導致在OSB側這個連接被并沒有感知到。
因此一直等待到600s的時候出現(xiàn)超時,而這個時候超時本身不是檢測到業(yè)務系統(tǒng)端出現(xiàn)問題的超時,或其它原因?qū)е逻@個thread被stuck,連接被掛起。因此又等待了900秒后出現(xiàn)了連接重置。
基于上面的分析我們進一步查找900s相關的設置,在Weblogic的DataSource連接池里面有一個900s收縮頻率的設置,該900s的含義為:在收縮為滿足需要而增大了的連接池前需等待的秒數(shù)。如果設置為 0,則將禁用收縮。而現(xiàn)在這個值我們設置為900s。
進一步查找資料,找到進一步信息為:
在Weblogic Server日志中可以觀察到大量的Connection for pool "SCDS" closed信息,表示系統(tǒng)在某一時刻會批量關閉一批連接,一般斷掉物理連接會這么做(WebLogic 配置池收縮也會這么做,如果未配置的話默認為900s檢查一次,從您的配置文件發(fā)現(xiàn)未配置池收縮)。從線程名稱看,是應用程序的線程關閉了連接。
即在600s連接出現(xiàn)掛起的時候,一直等待900s,在weblogic連接池檢查和收縮的時候才將該連接正式關閉和回收掉,從而返回Connection Reset的錯誤。
該假設還沒有得到進一步的驗證,但是從整個過程和日志分析來看,基本能夠說得通。
在該問題分析中,我們最大的一個錯誤分析就是根據(jù)300s和1500s想當然的判斷是重試了5次導致,而一直在查找為何會進行重試,而對重試配置進行檢查和驗證。
簡單來說就是前面的假設本身就是錯誤的,但是驗證假設上走太多彎路。因此還得重新回到問題本身。
前面分析了在600秒出現(xiàn)線程阻塞和掛起的時候,再等待了900秒出現(xiàn)連接超時,因此從時間上看是1500秒超時。
為了印證這個假設,我們將Read Time out的時間修改為400秒,那么就應該是1300秒報出服務超時的異常錯誤,但是最終測試的結果仍然是1500秒超時。
因此前面這個假設不成立。
對于該超時,在OSB集群側沒有任何5分鐘超時的設置,而檢查F5負載均衡的超時配置文檔可以看到,F(xiàn)5負載均衡設備上有一個idle time out的超時設置,默認就是300秒。
任何問題的診斷分析,往往無法提出明確合理的假設時候,仍然需要回歸到問題產(chǎn)生過程和鏈路,然后通過分而治之的方式確定具體的問題點和邊界。
因此為了解決該問題,首先還是要確定是否和負載均衡設備有關系。對于當前的服務調(diào)用,需要通過經(jīng)過ESB服務集群,業(yè)務系統(tǒng)的服務集群,才能夠完成。如下:

即整個服務請求的調(diào)用過程是為1->2->3->4的順序,需要同時經(jīng)過1和3兩個負載均衡設備。那么整個服務調(diào)用超時就和1,2,3,4四個節(jié)點的配置都會相關。
因此為了進一步進行驗證,我們嘗試對如下路徑直接調(diào)用以排查問題:
- 不走業(yè)務系統(tǒng)的負載均衡 1-2-4路徑調(diào)用
在該模式下通過管控系統(tǒng)和通過SOAPUI分別進行調(diào)用測試。發(fā)現(xiàn)整體調(diào)用能夠成功,有成功的實例返回。
對于通過管控調(diào)用的時候會出現(xiàn)有重試的現(xiàn)象,但是通過SOAPUI調(diào)用的時候沒有發(fā)現(xiàn)重試。
其次對于客戶端調(diào)用仍然會出現(xiàn)5分鐘調(diào)用超時,返回Connection Reset的錯誤。但是這個時候?qū)嶋H上服務仍然還運行,即2-4的連接仍然在運行并能夠成功運行完,因此可以看到成功的服務運行實例數(shù)據(jù)。
- 不走ESB和業(yè)務系統(tǒng)兩邊的集群,走2-4直接進行接口服務調(diào)用
在該模式下,我們通過SOAPUI對接口服務進行調(diào)用測試,能夠成功調(diào)用,有成功的實例返回,同時對于客戶端也可能得到成功的返回信息。
即既有成功的實例,客戶端也返回成功。即我們希望達到的一個結果。
- 走兩邊的集群模式 1-2-3-4路徑進行調(diào)用
這個即是最初的調(diào)用模式,我們還是使用SOAPUI進行調(diào)用,發(fā)現(xiàn)會出現(xiàn)調(diào)用重試,同時最終服務運行失敗,報1500秒的超時錯誤。
在客戶端也會報出連接超時錯誤。即和我們最初看的現(xiàn)象是一致的。但是具體為何會發(fā)起5分鐘后的重試,以及是否該重試是由負載均衡設備發(fā)起的暫時不明確。
在負載均衡上面,我們看到有tcp_tw_recycle參數(shù)配置,但是暫時不確定自動觸發(fā)重試是否和該參數(shù)的設置有關系,從網(wǎng)上文章來看是不建議對該參數(shù)配置進行啟用。
該超時問題經(jīng)過分析,基本確定是負載均衡的超時設置引起的。因此解決就簡單的,即對兩個集群對應的負載均衡超時設置都進行調(diào)整,同時確保該超時時間>OSB服務配置中的Read Time out時間即可。
最終問題得以解決。
四、JVM內(nèi)存溢出問題分析
網(wǎng)上有很多關于Java JVM內(nèi)存溢出的問題和解決方案,實際上對于這類問題已經(jīng)屬于一種很常見的問題,已經(jīng)形成了一種標準的問題解決和診斷方法論。
最佳方法就是按照這個步驟去診斷,而不是靠你自己經(jīng)驗去提出各種假設,因為在這種情況下你提出的假設很可能都是瞎猜,反而浪費了大量時間。
既對于問題在你沒有足夠經(jīng)驗的時候一定遵循通用方法論步驟去解決。
再回到內(nèi)存溢出問題,這個問題通用步驟如下:
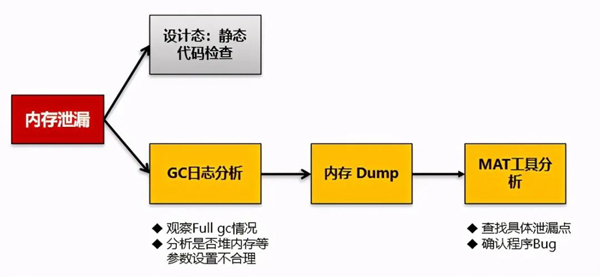
到了這里,我們基本回歸到通用問題解決方法論。
由于是生產(chǎn)環(huán)境問題,而且由于是商用產(chǎn)品,我無法在測試環(huán)境重現(xiàn),也無法進行靜態(tài)代碼檢查。因此首先還是需要進行Java GC的內(nèi)存回收日志分析。
對于JVM內(nèi)存溢出問題詳細分析可以參考:《從表象到根源-一個軟件系統(tǒng)JVM內(nèi)存溢出問題分析解決全過程》。(http://blog.sina.com.cn/s/blog_493a84550102z8m1.html)
五、業(yè)務系統(tǒng)性能問題分析診斷
如果一個業(yè)務系統(tǒng)上線前沒有性能問題,而在上線后出現(xiàn)了比較嚴重的性能問題,那么實際上潛在的場景主要來自于以下幾個方面:
- 業(yè)務出現(xiàn)大并發(fā)的訪問,導致出現(xiàn)性能瓶頸;
- 上線后的系統(tǒng)數(shù)據(jù)庫數(shù)據(jù)日積月累,數(shù)據(jù)量增加后出現(xiàn)性能瓶頸;
- 其它關鍵環(huán)境改變,比如我們常說的網(wǎng)絡帶寬影響。
正是由于這個原因,當我們發(fā)現(xiàn)性能問題的時候,首先就需要判斷是單用戶非并發(fā)狀態(tài)下本身就有性能問題,還是說在并發(fā)狀態(tài)才存在性能問題。
對于單用戶性能問題往往比較容易測試和驗證,對于并發(fā)性能問題我們可以在測試環(huán)境進行加壓測試和驗證,以判斷并發(fā)下的性能。
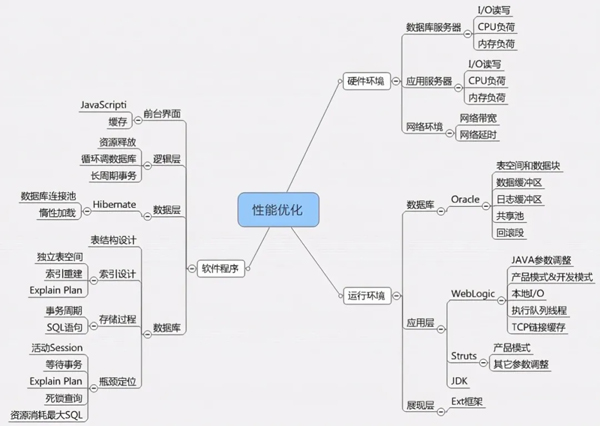
對于詳細的業(yè)務系統(tǒng)性能問題分析和診斷可以參考:《業(yè)務系統(tǒng)性能問題診斷和優(yōu)化分析》。(http://blog.sina.com.cn/s/blog_493a84550102z8t2.html)


